15. Имитационное моделирование
Цели
Имитация — это попытка дублировать особенности, внешний вид и характеристики реальной системы. Идея имитации реализуется следующим образом:
1) математическое описание реальной ситуации;
2) изучение ее свойств и особенностей;
3) формирование выводов и принятие решений, связанных с воздействием на эту ситуацию и основанных на результатах имитации.
Важно, что реальная система не подвергается воздействию до тех пор, пока преимущества или недостатки тех или иных управленческих решений не будут оценены с помощью модели этой системы.
После того как вы выполните задания, предлагаемые в этой главе, вы. будете уметь использовать для экономического анализа:
• имитацию;
• интервал случайных чисел;
• метод Монте-Карло;
• таблицу случайных чисел.
Модели
Метод Монте-Карло (метод статистических испытаний) состоит из четырех этапов:
1. Построение математической модели системы, описывающей зависимость моделируемых характеристик от значений стохастических переменных.
2. Установление распределения вероятностей для стохастических переменных.
3. Установление интервала случайных чисел для каждой стохастической переменной и генерация случайных чисел.
4. Имитация поведения системы путем проведения многих испытаний и получение оценки моделируемой характеристики системы при фиксированных значениях параметров управления. Оценка точности результата.
Описание этапов:
Первый этап. Стохастическая имитационная модель (ИМ) некоторой реальной системы может быть представлена как динамическая система, которая под воздействием внешних случайных входных сигналов (входных переменных) изменяет свое состояние (случайные переменные состояния), что в свою очередь приводит к изменению выходных сигналов (выходных переменных):
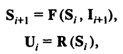
Где F, R — вектор-функции;
II, UI, SI — векторы соответственно входных, выходных переменных и переменных состояния системы в тактовый момент моделирования I.
Имитационная модель — это экспериментальная модель системы, в которой искусственно воспроизводятся случайности, имеющие место в реальной системе. Она представляет собой совокупность математических соотношений между входными, выходными переменными и переменными состояния в сочетании с алгоритмической реализацией некоторых зависимостей.
Существует два подхода в имитационном моделировании динамических процессов.
Первый заключается в том, что весь период моделирования разбивается на равные промежутки времени (такты моделирования) и анализ состояния системы, а также значений выходных переменных производится через одинаковые промежутки времени. При таком подходе возникает проблема выбора «правильной» продолжительности такта. Кроме того, не исключается появление тактов, в которых состояние системы по сравнению с предыдущим не изменилось.
При Втором подходе величина такта моделирования не фиксируется, моделирование в этом случае происходит в момент наступления одного из «существенных» событий. Например, при моделировании производственного процесса на предприятии такими событиями могут быть освобождение или начало загрузки станка, поступление на обработку детали, невыход на работу станочника, исчерпание запаса необходимых комплектующих деталей на складе и др. Именно второй подход чаще всего используется на практике и поддерживается современными языками моделирования.
Второй этап. Случайные величины, используемые в ИМ, могут быть дискретными или непрерывными. В первом случае необходимо знать Их распределения, во втором — Плотности распределений. Эти зависимости могут быть известны из теории, определены в результате специальных исследований либо заданы в качестве гипотезы. Точность модели (при прочих равных условиях) зависит от того, насколько точно заданы указанные распределения (плотности распределений).
Третий этап. Моделирование случайных величин при компьютерных имитационных экспериментах производится с помощью датчика псевдослучайных чисел, предусмотренного в любом современном языке программирования. Обычно это датчик случайных чисел с равномерным распределением на интервале [0, 1]. Если известны вероятности наступления событий, то, используя такой датчик, можно отвечать на вопросы: «Какое из N возможных событий произошло?» или «Какое значение приняла случайная величина?»
Предположим, что в ИМ используется случайная величина X, Принимающая дискретные значения Х1, х2,..., ХN с вероятностями соответственно P1, P2,..., PN ( ). Получение некоторой реализации этой переменной в модели производится следующим образом.
Строится функция распределения случайной величины X. Указанная функция определяется посредством равенства F(X) = åPk, в котором суммирование распространяется на все индексы, для которых ХK < X. С помощью датчика случайных чисел получают случайное число И из отрезка [0, 1].
Из равномерности распределения получаемых случайных чисел следует, что вероятность получения случайного числа из произвольного интервала, включенного в [0, 1], равна длине этого интервала. Поэтому вероятность реализации Х = хK равна вероятности попадания полученного от датчика случайного числа И В произвольный интервал длиной Pk на отрезке [0, 1]. Можно, таким образом, утверждать, что если очередное число И датчика удовлетворяет неравенствам 0 < И £ р1, то имеет место реализация Х = х1, в случае P1 < и £ p1 + Р2 — реализация Х = х2 и т. д. В общем случае для K = 2, ..., N: если ![]() < и £
< и £ ![]() , то Х = хK.
, то Х = хK.
Заметим, что границы указанных неравенств совпадают со значениями построенной выше функции распределения F(X).
Удобнее, однако, иметь дело не с дробными значениями границ интервалов, в которые попадает случайное число И, а с их Целочисленными значениями, тем более, что с помощью датчиков случайных чисел можно генерировать числа из любого диапазона. Чтобы получить целые значения границ интервалов, достаточно умножить все Pk на 10D, где D — целое, минимальное значение которого равно максимальной точности (максимальному числу знаков после десятичной точки) чисел Pk, K = 1,..., N. Например, если {РK} = {0,3; 0,153; 0,5; 0,047}, то минимальное значение D равно 3 (все РK Нужно умножить на 1000). Таким образом, 10D определяет длину интервала значений рассматриваемой случайной величины в ИМ.
Четвертый этап. Точность статистических оценок параметров реальной системы зависит от числа наблюдений (объема выборки). Погрешности в оценках обусловлены как статистическим характером самой модели, так и влиянием начальных данных (начального состояния имитационной системы), а также возможной автокорреляцией последовательных значений некоторого параметра в процессе моделирования. Очевидно, что с увеличением числа испытаний точность моделирования должна возрастать. Ввиду того что увеличение объема выборки связано с ростом затрат на моделирование, важно уметь определять минимальное число испытаний, необходимое для достижения заданной точности оценки с заданной вероятностью.
Широкое распространение получили два метода статистических испытаний. Один из них предполагает проведение достаточно большого числа Т последовательных наблюдений в течение одного прогона модели (одного сеанса имитирования).
Другой метод заключается в реализации Т независимых прогонов модели, т. е. в M-кратном повторении одного и того же цикла имитирования. При этом, если мы хотим получить в сумме Т Наблюдений, в течение каждого прогона можно делать по Т/т (допустим, что это число целое) наблюдений. Оба метода дают примерно одинаковый результат.
Пусть значения УT (T = 1,..., Т) представляют собой результаты Т последовательных измерений значений случайной величины Y во время одного и того же сеанса имитации. Среднее по времени значение у определяется выражением
![]()
Обозначим через m математическое ожидание случайной величины У. Тогда для достаточно большого T получаем
![]()
Оценка дисперсии ![]() (если временной ряд не является автокоррелированным) имеет вид
(если временной ряд не является автокоррелированным) имеет вид
![]()
Где D(У) — дисперсия случайной величины У.
Для оценки качества результатов, полученных методом Монте-Карло при неизвестной дисперсии наблюдаемой случайной величины, предположим, что Z — характеристика, которая должна быть определена (вероятность события, математическое ожидание, дисперсия и т. п.), a x — ее значение, уточняемое по мере накопления данных, остающееся случайным вследствие ограниченности числа T проведенных наблюдений. В этих условиях можно говорить о вероятности P(|Z – x| < e) по отношению к интересующей нас характеристике. Величина |Z – e| представляет собой погрешность в оценке Z, a e — некоторый допустимый ее предел.
Из неравенства Чебышёва следует
![]()
Из этого неравенства следует
![]()
Откуда при заданных Р и e и при известной зависимости DE (Т) можно найти предельно необходимое Т.
Известно, что истинная дисперсия выборочного распределения для расчетного среднего обратно пропорциональна суммарному числу наблюдений Т, т. е.
![]()
Где D не зависит от Т.
В начале имитационного процесса требуемое число наблюдений определить обычно не удается, поскольку D неизвестно. Поэтому, как правило, эксперимент проводят в два этапа.
На первом этапе число испытаний выбирается относительно небольшим, в результате определяется величина D. После этого можно уже определить, сколько дополнительных наблюдений необходимо, чтобы была достигнута требуемая точность.
Предельное число наблюдений Т0 определяется формулой T0 = d/[(1 – P)e2].
При любом числе наблюдений больше Т0 обеспечивается требуемая точность.
| < Предыдущая | Следующая > |
|---|