03. Модель парной линейной регрессии
Методам простой или парной регрессии и корреляции, возможностям их применения в эконометрике посвящен данный раздел.
Любое эконометрическое исследование начинается со Спецификации модели, т. е. с формулировки вида модели исходя из соответствующей теории связи между переменными.
Парная регрессия достаточна, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной.
Уравнение простой регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем по совокупности наблюдений. Например, если зависимость спроса у от цены х будет характеризоваться уравнением ![]() , то это означает, что с ростом цены на 1 д. е. спрос в среднем уменьшается на 2 д. е. В уравнении регрессии корреляционная по сути связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией. Практически в каждом отдельном случае величина у складывается из двух слагаемых:
, то это означает, что с ростом цены на 1 д. е. спрос в среднем уменьшается на 2 д. е. В уравнении регрессии корреляционная по сути связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией. Практически в каждом отдельном случае величина у складывается из двух слагаемых:
![]() , (1.1)
, (1.1)
Где ![]() – фактическое значение результативного признака;
– фактическое значение результативного признака;
![]() – теоретическое значение результативного признака, найденное исходя из соответствующей математической функции связи у и х, т. е. их уравнения регрессии;
– теоретическое значение результативного признака, найденное исходя из соответствующей математической функции связи у и х, т. е. их уравнения регрессии;
![]() – случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии.
– случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии.
Случайная величина ε, или Возмущение, Включает влияние неучтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели обусловлено тремя источниками: спецификацией модели, выборочным характером исходных данных и особенностями измерения переменных.
При правильно выбранной спецификации модели зависит величина случайных ошибок, поэтому, чем они меньше, тем в большей мере теоретические значения результативного признака ![]() подходят к фактическим данным
подходят к фактическим данным ![]() .
.
К ошибкам спецификации будет относится не только неправильный выбор той или иной математической функции для ![]() , но и недоучет в уравнении регрессии какого-либо существенного фактора, т. е. использование парной регрессии вместо множественной.
, но и недоучет в уравнении регрессии какого-либо существенного фактора, т. е. использование парной регрессии вместо множественной.
Наряду с ошибками спецификации могут иметь место ошибки выборки, поскольку исследователь чаще всего работает с выборочными данными при установлении закономерной связи между признаками. Ошибки выборки имеют место и в силу неоднородности данных в исходной статистической совокупности, что, как правило, бывает при изучении эконометрических процессов. Если совокупность неоднородна, то уравнение регрессии не имеет практического смысла.
Наибольшую опасность в практическом использовании методов регрессии представляют ошибки измерения. Если ошибки спецификации можно уменьшить, изменяя форму модели (вид математической формулы), а ошибки выборки – увеличивая объем исходных данных, то ошибки измерения практически сводят на нет все усилия по количественной оценке связи между признаками.
Предполагая, что ошибки измерения сведены к минимуму, основное внимание в эконометрических исследованиях уделяется ошибкам спецификации модели.
В парной регрессии выбор вида математической функции ![]() может быть осуществлен тремя методами:
может быть осуществлен тремя методами:
- графическим;
- аналитическим, т. е. исходя из теории изучаемой взаимосвязи;
- экспериментальным.
При изучении зависимости между двумя признаками Графический метод подбора вида уравнения регрессии достаточно нагляден. Он базируется на поле корреляции.
Класс математических функций для описания связи двух переменных достаточно широк. Кроме уже указанных используются и другие типы кривых:
![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() ;
; ![]() .
.
Значительный интерес представляет Аналитический метод выбора типа уравнения регрессии. Он основан на изучении материальной природы связи исследуемых признаков.
При обработке информации на компьютере выбор вида уравнения регрессии обычно проводится экспериментальным методом, т. е. путем сравнения величины остаточной дисперсии Dост, рассчитанной при разных моделях.
Если уравнение регрессии проходит через все точки корреляционного поля, что возможно только при функциональной связи, когда все точки лежат на линии регрессии ![]() , то фактические значения результативного признака совпадают с теоретическими
, то фактические значения результативного признака совпадают с теоретическими ![]() , т. е. они полностью обусловлены влиянием фактора х. в этом случае остаточная дисперсия Dост=0. В практических исследованиях, как правило, имеет место некоторое рассеяние точек относительно линии регрессии. Оно обусловлено влиянием прочих не учитываемых в уравнении регрессии факторов. Иными словами, имеют место отклонения фактических данных от теоретических (у-
, т. е. они полностью обусловлены влиянием фактора х. в этом случае остаточная дисперсия Dост=0. В практических исследованиях, как правило, имеет место некоторое рассеяние точек относительно линии регрессии. Оно обусловлено влиянием прочих не учитываемых в уравнении регрессии факторов. Иными словами, имеют место отклонения фактических данных от теоретических (у-![]() ). Величина этих отклонений и лежит в основе расчета остаточной дисперсии:
). Величина этих отклонений и лежит в основе расчета остаточной дисперсии:
 . (1.2)
. (1.2)
Чем меньше величина остаточной дисперсии, тем в меньшей мере наблюдается влияние прочих не учитываемых в уравнении регрессии факторов и тем лучше уравнение регрессии подходит к исходным данным.
Линейная регрессия находит широкое применение в эконометрике ввиду четкой экономической интерпретацией ее параметров.
Линейная регрессия сводится к нахождению уравнения вида
![]() или
или ![]() . (1.3)
. (1.3)
Построение линейной регрессии сводится к оценке ее параметров – а и b. Классический подход к оцениванию параметров линейной регрессии основан на Методе наименьших квадратов (МНК).
МНК позволяет получить такие оценки параметров а и b, при которых сумма квадратов отклонений фактических значений результативного признака у от расчетных (теоретических) ![]() минимальна:
минимальна:
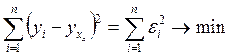 . (1.4)
. (1.4)
Иными словами, из всего множества линий линия регрессии на графике выбирается так, чтобы сумма квадратов расстояний по вертикали между точками и этой линией была минимальной.
Для того чтобы найти минимум функции 1.4, надо вычислить частные производные по каждому из параметров а и b и приравнять их к нулю. Обозначим ![]() через S, тогда:
через S, тогда:
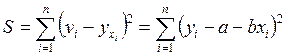 ;
;
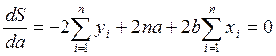 ; (1.5)
; (1.5)
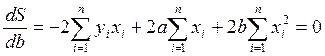 .
.
Преобразуя формулу 1.5, получим следующую систему нормальных уравнений для оценки параметров а и b:
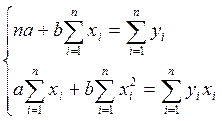 . (1.6)
. (1.6)
Решая систему нормальных уравнений 1.6 либо методом последовательного исключения переменных, либо методом определителей, найдем искомые оценки параметров а и b. Можно воспользоваться следующими формулами для а и b:
![]() . (1.7)
. (1.7)
Формула 1.7. получена из первого уравнения системы 1.6, если все его члены разделить на n:
 ,
,
Где ![]() - ковариация признаков;
- ковариация признаков;
![]() - дисперсия признака х.
- дисперсия признака х.
Поскольку ![]() , а
, а ![]() , получим следующую формулу расчета оценки параметра b:
, получим следующую формулу расчета оценки параметра b:
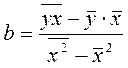 . (1.8)
. (1.8)
Формула 1.8 получается также при решении системы 1.6 методом определителей, если все элементы расчета разделить на n2.
Параметр b называется коэффициентом регрессии. Его величина показывает среднее изменение результата с изменением фактора на одну единицу. Знак при коэффициенте регрессии b показывает направление связи: при b>0 – связь прямая, а при b<0 – связь обратная.
Формально а – значение у при х=0. Если признак-фактор х не имеет и не может иметь нулевого значения, то трактовка свободного члена а не имеет смысла. Параметр а может не иметь экономического содержания. Попытки интерпретировать экономически параметр а могут привести к абсурду, особенно при a<0. Интерпретировать можно лишь знак при параметре а. Если a>0, то относительное изменение результата происходит медленнее, чем изменение фактора.
Уравнение регрессии всегда дополняется показателем тесноты связи. При использовании линейной регрессии в качестве такого показателя выступает линейный коэффициент корреляции rxy. Имеются разные модификации формулы линейного коэффициента корреляции, например:
 , (1.9)
, (1.9)
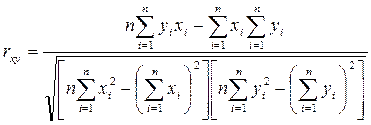 . (1.10)
. (1.10)
Значение линейного коэффициента корреляции находится в границах ![]() . Если коэффициент регрессии b>0, то 0
. Если коэффициент регрессии b>0, то 0![]() , и, наоборот, при b<0 -
, и, наоборот, при b<0 - ![]() . Следует отметить, что величина линейного коэффициента корреляции оценивает тесноту связи рассматриваемых признаков в ее линейной форме. Чем ближе значение данного коэффициента к 1, тем связь между показателями сильнее, чем ближе к нулю, тем связь слабее.
. Следует отметить, что величина линейного коэффициента корреляции оценивает тесноту связи рассматриваемых признаков в ее линейной форме. Чем ближе значение данного коэффициента к 1, тем связь между показателями сильнее, чем ближе к нулю, тем связь слабее.
Для оценки качества подбора линейной функции рассчитывается квадрат линейного коэффициента корреляции ![]() , называемый Коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака у, объясняемую регрессией, в общей дисперсии результативного признака:
, называемый Коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака у, объясняемую регрессией, в общей дисперсии результативного признака:
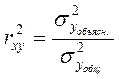 . (1.11)
. (1.11)
Соответственно величина 1-r2 характеризует долю дисперсии у, вызванную влиянием остальных не учтенных в модели факторов. Величина коэффициента детерминации является одним из критериев оценки качества линейной модели. Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов и, следовательно, линейная модель хорошо объясняет исходные данные, и ею можно воспользоваться для прогноза значений результативного признака.
Коэффициенты регрессии – величины именованные, и потому несравнимы для разных признаков. Так, коэффициент регрессии по модели прибыли предприятия от состава выпускаемой продукции несопоставим с коэффициентом регрессии прибыли предприятия от затрат на рекламу.
Сделать коэффициенты регрессии сопоставимыми по разным признакам позволяет определение аналогичного показателя в стандартизованной системе единиц, где в качестве единицы измерения признака используется его среднее квадратическое отклонение (σ). Поскольку коэффициент регрессии b имеет единицы измерения дробные (результат/фактор), то умножив его на среднее квадратическое отклонение фактора х (σх) и разделив на среднее квадратическое отклонение результата (σу), получим показатель, пригодный для сравнения интенсивности изменения результата под влиянием разных факторов. Иными словами, мы вернулись к формуле линейного коэффициента корреляции. Его величина выступает в качестве стандартизованного коэффициента регрессии и характеризует среднее в сигмах (σу) изменение результата с изменением фактора на одну σх.
Линейный коэффициент корреляции как измеритель тесноты линейной связи признаков логически связан не только с коэффициентом регрессии b, но и с коэффициентом эластичности, который является показателем силы связи, выраженным в процентах. При линейной связи признаков х и у средний коэффициент эластичности в целом по совокупности определяется как ![]() и характеризует, на сколько % в среднем изменится у при увеличении фактора x на 1%.
и характеризует, на сколько % в среднем изменится у при увеличении фактора x на 1%.
Несмотря на схожесть этих показателей, измерителем тесноты связи выступает линейный коэффициент корреляции (rxy), а коэффициент регрессии (b) и коэффициент эластичности (Э) – показатели силы связи; коэффициент регрессии является абсолютной мерой, ибо имеет единицы измерения, присущие изучаемым признакам у и х, а коэффициент эластичности - относительным показателем силы связи, потому что выражен в процентах.
После того как уравнение линейной регрессии найдено, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю, т. е. b=0, и, следовательно, фактор х не оказывает влияния на результат у.
Непосредственному расчету F-критерия предшествует анализ дисперсии. Центральное место в нем занимает разложение общей суммы квадратов отклонений переменной у от среднего значения ![]() на две части – «объясненную» и «остаточную» («необъясненную»):
на две части – «объясненную» и «остаточную» («необъясненную»):
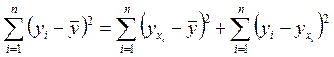 . (1.12)
. (1.12)
|
Общая сумма квадратов отклонений |
= |
Сумма квадратов отклонений, объясненная регрессией |
+ |
Остаточная сумма квадратов отклонений |
Любая сумма квадратов отклонений связана с числом степеней свободы df, т. е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант.
Так, для общей суммы квадратов ![]() необходимо (n-1) независимых отклонений, ибо из совокупности из n единиц после расчета среднего уровня свободно варьируют лишь (n-1) число отклонений. Например, имеем ряд значений у: 1,2,3,4,5. Среднее из них равно 3, и тогда n отклонений от среднего составят: -2, -1, 0, 1, 2. Видим, что свободно варьируют только четыре отклонения, а пятое может быть определено, если четыре предыдущие известны.
необходимо (n-1) независимых отклонений, ибо из совокупности из n единиц после расчета среднего уровня свободно варьируют лишь (n-1) число отклонений. Например, имеем ряд значений у: 1,2,3,4,5. Среднее из них равно 3, и тогда n отклонений от среднего составят: -2, -1, 0, 1, 2. Видим, что свободно варьируют только четыре отклонения, а пятое может быть определено, если четыре предыдущие известны.
При расчете объясненной, или факторной, суммы квадратов ![]() используются теоретические (расчетные) значения результативного признака
используются теоретические (расчетные) значения результативного признака ![]() , найденные по линии регрессии:
, найденные по линии регрессии: ![]() . Вследствие чего факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
. Вследствие чего факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет n-2.
Итак, имеем два равенства:
- 1)
; 2) Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим Средний квадрат отклонений или Дисперсию на одну степень свободы D.
 ;
; 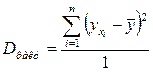 ;
; 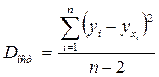 .
.
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-отношения, т. е. критерия F:
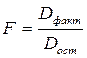 . (1.13)
. (1.13)
Если нулевая гипотеза Н0 справедлива, то факторная и остаточная дисперсия не отличаются друг от друга. Если Н0 несправедлива, то факторная дисперсия превышает остаточную в несколько раз. Кроме расчетных значений F-критерия существуют также и табличные. Табличные значения F-критерия – это максимальная величина отношений дисперсий, которая может быть иметь место при случайном расхождении их для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения признается достоверным (отличным от единицы), если оно больше табличного. В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи: Fфакт>Fтабл, Н0 отклоняется. Если же величина F окажется меньше табличной, то вероятность нулевой гипотезы выше заданного уровня (например, 0,05) и она не может быть отклонена без риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически незначимым: Fфакт<Fтабл, Н0 не отклоняется.
Величина F-критерия связана с коэффициентом детерминации r2. Факторную сумму квадратов отклонений можно представить как
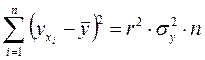 ,
,
А остаточную сумму квадратов – как
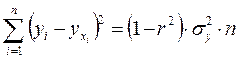 .
.
Тогда значение F-критерия можно выразить следующим образом:
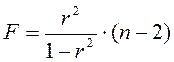 . (1.14)
. (1.14)
Для измерения точности построенной модели используется Средняя относительная ошибка аппроксимации
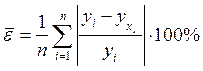 . (1.15)
. (1.15)
Для экономических исследований применяются следующие уровни ошибки аппроксимации: если ![]() до 10%, то построенное уравнение регрессии достаточно точно выражает закон изменения исследуемого показателя под действием факторов и приемлемо для целей анализа; в случае построения модели для прогнозирования, допустимое значение
до 10%, то построенное уравнение регрессии достаточно точно выражает закон изменения исследуемого показателя под действием факторов и приемлемо для целей анализа; в случае построения модели для прогнозирования, допустимое значение ![]() до 4%.
до 4%.
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка: mb и ma.
Стандартная ошибка коэффициента регрессии параметра mb рассчитывается по формуле:
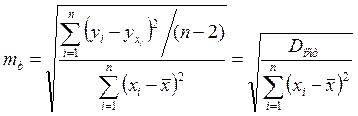 , (1.16)
, (1.16)
Отношение коэффициента регрессии к его стандартной ошибке дает t-статистику, которая подчиняется статистике Стьюдента при (n-2) степенях свободы. Эта статистика применяется для проверки статистической значимости коэффициента регрессии и для расчета его доверительных интервалов.
Для оценки значимости коэффициента регрессии его величину сравнивают с его стандартной ошибкой, т. е. определяют фактическое значение t-критерия Стьюдента:
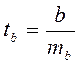 , (1.17)
, (1.17)
Которое затем сравнивают с табличным значением при определенном уровне значимости α и числе степеней свободы (n-2).
Если фактическое значение t-критерия превышает табличное, гипотезу о несущественности коэффициента регрессии можно отклонить. Доверительный интервал для коэффициента регрессии определяется как ![]() .
.
Стандартная ошибка параметра а определяется по формуле
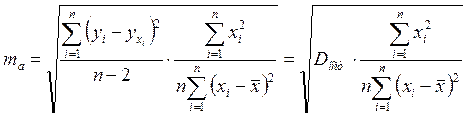 . (1.18)
. (1.18)
Процедура оценивания значимости данного параметра не отличается от рассмотренной выше для коэффициента регрессии: вычисляется t-критерий:
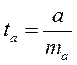 , (1.19)
, (1.19)
Его величина сравнивается с табличным значением при (n-2) степенях свободы.
Значимость линейного коэффициента корреляции проверяется на основе величины ошибки коэффициента корреляции mr:
 . (1.20)
. (1.20)
Фактическое значение t-критерия Стьюдента определяется как
 . (1.21)
. (1.21)
Рассмотренную формулу оценки коэффициента корреляции рекомендуется применять при большом числе наблюдений, а также, если r не близко к +1 или -1.
В прогнозных расчетах по уравнению регрессии определяется предсказываемое ур значение как точечный прогноз ![]() при хр=хк, т. е. путем подстановки в линейное уравнение регрессии
при хр=хк, т. е. путем подстановки в линейное уравнение регрессии ![]() соответствующего значения х. Однако точечный прогноз явно нереален, поэтому он дополняется расчетом стандартной ошибки
соответствующего значения х. Однако точечный прогноз явно нереален, поэтому он дополняется расчетом стандартной ошибки ![]() , т. е.
, т. е. ![]() , и соответственно мы получаем интервальную оценку прогнозного значения у*:
, и соответственно мы получаем интервальную оценку прогнозного значения у*:
![]() . (1.22)
. (1.22)
Для того чтобы понять, как строится формула для определения величин стандартной ошибки ![]() , подставим в уравнение линейной регрессии выражение параметра а:
, подставим в уравнение линейной регрессии выражение параметра а: ![]() , тогда уравнение регрессии примет вид:
, тогда уравнение регрессии примет вид:
![]() .
.
Отсюда следует, что стандартная ошибка ![]() зависит от ошибки
зависит от ошибки ![]() и ошибки коэффициента регрессии b, т. е.
и ошибки коэффициента регрессии b, т. е.
![]() . (1.23)
. (1.23)
Из теории выборки известно, что ![]() . Используя в качестве оценки
. Используя в качестве оценки ![]() остаточную дисперсию на одну степень свободы Dост, получим формулу расчета ошибки среднего значения переменной у:
остаточную дисперсию на одну степень свободы Dост, получим формулу расчета ошибки среднего значения переменной у:
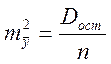 . (1.24)
. (1.24)
Ошибка коэффициента регрессии определяется формулой 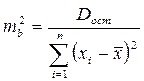 . Считая, что прогнозное значение фактора хр=хк, получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, т. е.
. Считая, что прогнозное значение фактора хр=хк, получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, т. е. ![]() :
:
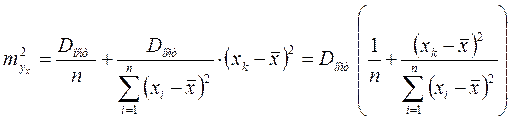 . (1.25)
. (1.25)
Соответственно ![]() имеет выражение:
имеет выражение:
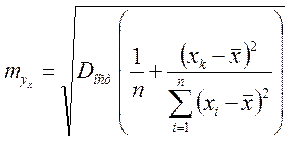 . (1.26)
. (1.26)
Рассмотренная формула стандартной ошибки предсказываемого среднего значения у при заданном значении хк характеризует ошибку положения линии регрессии. Величина стандартной ошибки ![]() достигает минимума при
достигает минимума при ![]() и возрастает по мере того, как «удаляется» от
и возрастает по мере того, как «удаляется» от ![]() в любом направлении.
в любом направлении.
Графически доверительные интервалы для ![]() будут выглядеть как гиперболы, расположенные по обе стороны от линии регрессии, см. рис. 2.
будут выглядеть как гиперболы, расположенные по обе стороны от линии регрессии, см. рис. 2.
Средняя ошибка прогнозируемого индивидуального значения у составит: 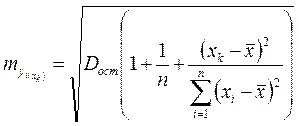 .
.
| |
| |
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. рассмотренная формула средней ошибки индивидуального значения признака ![]() может быть использована также для оценки существенности различия предсказываемого значения и некоторого гипотетического значения.
может быть использована также для оценки существенности различия предсказываемого значения и некоторого гипотетического значения.
Вопросы для самопроверки
1. В чем состоят ошибки спецификации модели?
2. Поясните смысл коэффициента регрессии, назовите способы его оценивания.
3. Что такое число степеней свободы и как оно определяется для факторной и остаточной сумм квадратов?
4. Какова концепция F-критерия Фишера?
5. Как оценивается значимость параметров уравнения регрессии?
6. Как определяется коэффициент эластичности и что он показывает?
7. В чем смысл средней ошибки аппроксимации и как она определяется?
| < Предыдущая | Следующая > |
|---|