2.07. Проверка статистических гипотез . о значениях коэффициентов
В только что рассмотренном примере мы построили ![]() — доверительный интервал для параметра
— доверительный интервал для параметра![]() в виде
в виде
![]()
Т. е.
![]()
Существенно, что При любом истинном значении параметра![]() вероятность накрытия этого значения построенным доверительным интервалом равна
вероятность накрытия этого значения построенным доверительным интервалом равна ![]() .
.
Рассмотрим значение![]() ; построенный интервал его Не накрывает. Однако если
; построенный интервал его Не накрывает. Однако если![]() Действительно равняется 1, то вероятность такого ненакрытия равна
Действительно равняется 1, то вероятность такого ненакрытия равна ![]() . Таким образом, факт ненакрытия значения
. Таким образом, факт ненакрытия значения ![]() построенным интервалом представляет (в случае, когда
построенным интервалом представляет (в случае, когда![]() ) осуществление довольно редкого события, имеющего малую вероятность
) осуществление довольно редкого события, имеющего малую вероятность ![]() , и это дает нам основания Сомневаться в том, что в действительности
, и это дает нам основания Сомневаться в том, что в действительности ![]() .
.
То же самое относится и к любому другому фиксированному значению ![]() , не принадлежащему указанному
, не принадлежащему указанному ![]() -доверительному интервалу: предположение о том, что В действительности
-доверительному интервалу: предположение о том, что В действительности ![]() , представляется маловероятным.
, представляется маловероятным.
Подобного рода предположения называют в этом контексте Статистическими гипотезами (statistical hypothesis). О Проверяемой гипотезе Говорят как об Исходной — «нулевой» (maintained, null) Гипотезе
И обозначают такую гипотезу символом ![]() , так что в последнем случае мы имеем дело с гипотезой
, так что в последнем случае мы имеем дело с гипотезой
![]()
В соответствии со сказанным выше, такую гипотезу естественно Отвергать (отклонять), если значение ![]() Не принадлежит
Не принадлежит ![]() -доверительному интервалу для
-доверительному интервалу для![]() , т. е. интервалу
, т. е. интервалу
![]()
Вспоминая, как этот интервал строился, мы замечаем, что![]() Не Принадлежит этому интервалу тогда и только тогда, когда
Не Принадлежит этому интервалу тогда и только тогда, когда

Т. е. когда наблюдаемое значение отношения
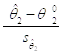
«слишком велико» по абсолютной величине. Последнее означает «Слишком большое» отклонение оценки ![]() от Гипотетического значения
от Гипотетического значения ![]() параметра
параметра ![]() , В сравнении с оценкой
, В сравнении с оценкой ![]() значения
значения ![]() корня из дисперсии оценки этого параметра.
корня из дисперсии оценки этого параметра.
Итак, если
Мы Отвергаем гипотезу ![]() . Однако выполнение этого неравенства для некоторого значения
. Однако выполнение этого неравенства для некоторого значения ![]() Вовсе не означает, что гипотеза
Вовсе не означает, что гипотеза ![]() Обязательно не верна. Если В действительности
Обязательно не верна. Если В действительности![]() , то все же имеется вероятность
, то все же имеется вероятность ![]() того, что это неравенство Будет выполнено.
того, что это неравенство Будет выполнено.
В последнем случае, В соответствии с выбранным правилом, мы все же Отвергнем Гипотезу ![]() , допустив при этом «Ошибку 1-го рода». Такая ошибка происходит в среднем в
, допустив при этом «Ошибку 1-го рода». Такая ошибка происходит в среднем в ![]() случаях из ста.
случаях из ста.
Если бы мы выбрали Произвольный Доверительный уровень ![]() , то тогда мы отвергали бы гипотезу
, то тогда мы отвергали бы гипотезу ![]() при выполнении неравенства
при выполнении неравенства
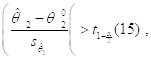
И ошибка 1-го рода происходила в среднем в ![]() случаев из
случаев из ![]() . Точнее, Вероятность ошибки 1-го рода была бы равна
. Точнее, Вероятность ошибки 1-го рода была бы равна ![]() :
:
![]()
![]() Отвергается
Отвергается![]()
![]() Верна
Верна![]() =
= ![]() .
.
Само Правило Решения вопроса об отклонении или неотклонении статистической гипотезы ![]() Называется Статистическим критерием проверки гипотезы Н0, а выбранное при формулировании этого правила значение A Называется Уровнем значимости критерия.
Называется Статистическим критерием проверки гипотезы Н0, а выбранное при формулировании этого правила значение A Называется Уровнем значимости критерия.
Выбор большего или меньшего значения A Определяется Степенью значимости для исследователя исходной гипотезы ![]() . Скажем, выбор между значениями
. Скажем, выбор между значениями ![]() и
и ![]() в пользу
в пользу ![]() означает, что исследователь Заранее настроен в пользу гипотезы
означает, что исследователь Заранее настроен в пользу гипотезы ![]() И ему требуются очень весомые Аргументы, свидетельствующие против этой гипотезы, чтобы все же отказаться от нее. Выбор же в пользу уровня значимости
И ему требуются очень весомые Аргументы, свидетельствующие против этой гипотезы, чтобы все же отказаться от нее. Выбор же в пользу уровня значимости ![]() означает, что исследователь Не столь сильно отстаивает гипотезу
означает, что исследователь Не столь сильно отстаивает гипотезу ![]() И готов отказаться от нее и при менее убедительной аргументации против этой гипотезы.
И готов отказаться от нее и при менее убедительной аргументации против этой гипотезы.
Всякий статистический критерий основывается на использовании той или иной Статистики (статистики критерия), т. е. случайной величины, значения которой Могут быть вычислены (по крайней мере, теоретически) на основании имеющихся статистических данных и распределение которой Известно (хотя бы приближенно).
В нашем примере критерий проверки гипотезы ![]() основывался на использовании T-статистики
основывался на использовании T-статистики
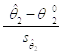 ,
,
Значение которой Можно вычислить по данным наблюдений, поскольку![]() — известное (заданное) число, а
— известное (заданное) число, а ![]() и
и ![]() вычисляются на основании данных наблюдений.
вычисляются на основании данных наблюдений.
Каждому статистическому критерию соответствует Критическое множество R Значений статистики критерия, при которых гипотеза ![]() Отвергается в соответствии с принятым правилом. В нашем примере таковым является множество значений указанной
Отвергается в соответствии с принятым правилом. В нашем примере таковым является множество значений указанной ![]() -статистики, превышающих по абсолютной величине значение
-статистики, превышающих по абсолютной величине значение ![]()
Итак, Статистический критерий Определяется заданием
A. Статистической гипотезы Н 0;
B. Уровня значимости A;
C. Статистики критерия;
D. Критического множества R.
Можно подумать, что пункты b) и d) Дублируют Друг друга, поскольку в нашем примере критическое множество ![]() Однозначно определяется по заданному уровню значимости
Однозначно определяется по заданному уровню значимости ![]() . Однако, как мы увидим в дальнейшем, одному и тому же уровню значимости можно сопоставить Различные критические множества, что дает возможность выбирать множество
. Однако, как мы увидим в дальнейшем, одному и тому же уровню значимости можно сопоставить Различные критические множества, что дает возможность выбирать множество ![]() Наиболее рациональным образом, В зависимости от выбора гипотезы
Наиболее рациональным образом, В зависимости от выбора гипотезы ![]() (выбор Наиболее мощного критерия).
(выбор Наиболее мощного критерия).
Компьютерные Пакеты программ статистического анализа данных Первоочередное внимание уделяют проверке гипотезы
![]()
В рамках нормальной модели множественной линейной регрессии
![]()
С ![]() ~ I. i. d.
~ I. i. d. ![]() . Эта гипотеза соответствует предположению исследователя о том, что
. Эта гипотеза соответствует предположению исследователя о том, что ![]() -я объясняющая переменная Не имеет существенного значения с точки зрения объяснения изменчивости значений объясняемой переменной
-я объясняющая переменная Не имеет существенного значения с точки зрения объяснения изменчивости значений объясняемой переменной ![]() , так что она может быть исключена из модели.
, так что она может быть исключена из модели.
Для соответствующего критерия
A. ![]() ;
;
B. уровень значимости ![]() по умолчанию обычно выбирается равным
по умолчанию обычно выбирается равным ![]() ;
;
C. статистика критерия имеет вид
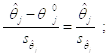
Если гипотеза ![]() верна, то эта статистика имеет
верна, то эта статистика имеет ![]() - Распределение Стьюдента с
- Распределение Стьюдента с ![]() степенями свободы,
степенями свободы,
![]() ~
~ ![]() ,
,
В связи с чем ее обычно называют T-статистикой (t-statistic) Или
T-отношением (t-ratio);
D) критическое множество имеет вид
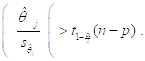
При этом, в распечатках результатов Регрессионного анализа (т. е. Статистического анализа модели линейной регрессии) сообщаются:
· значение оценки ![]() параметра
параметра ![]() в графе Коэффициенты (Coefficient);
в графе Коэффициенты (Coefficient);
· значение ![]() знаменателя T-Статистики в графе Стандартная ошибка (Std. Error);
знаменателя T-Статистики в графе Стандартная ошибка (Std. Error);
· значение отношения ![]() в графе T-статистика (t-statistic).
в графе T-статистика (t-statistic).
Кроме того, сообщается также
· вероятность того, что случайная величина, имеющая распределение Стьюдента с ![]() степенями свободы, примет значение, Не меньшее по абсолютной величине, чем Наблюденное значение
степенями свободы, примет значение, Не меньшее по абсолютной величине, чем Наблюденное значение ![]() — в графе Р-значение (Р-value Или Probability).
— в графе Р-значение (Р-value Или Probability).
В отношении полученного при анализе Р-Значения возможны следующие варианты.
Если указываемое P-Значение Меньше выбранного уровня значимости ![]() , то это равносильно тому, что значение T-Статистики
, то это равносильно тому, что значение T-Статистики ![]() Попало в Область отвержения гипотезы
Попало в Область отвержения гипотезы ![]() , т. е.
, т. е. ![]() В этом случае гипотеза
В этом случае гипотеза ![]() Отвергается.
Отвергается.
Если указываемое P-Значение Больше выбранного уровня значимости ![]() , то это равносильно тому, что значение T-Статистики
, то это равносильно тому, что значение T-Статистики ![]() Не попало в область отвержения гипотезы
Не попало в область отвержения гипотезы ![]() , т. е.
, т. е. ![]() В этом случае гипотеза
В этом случае гипотеза ![]() не отвергается.
не отвергается.
Если (в пределах округления) указываемое P-Значение Равно выбранному уровню значимости ![]() , то в отношении гипотезы
, то в отношении гипотезы ![]() можно принять Любое из двух возможных решений.
можно принять Любое из двух возможных решений.
В случае, когда гипотеза ![]() Отвергается (Вариант 1), говорят, что параметр
Отвергается (Вариант 1), говорят, что параметр![]() статистически значим (statistically significant); это соответствует признанию того, что наличие J-Й объясняющей переменной в правой части модели Существенно для объяснения наблюдаемой изменчивости объясняемой переменной.
статистически значим (statistically significant); это соответствует признанию того, что наличие J-Й объясняющей переменной в правой части модели Существенно для объяснения наблюдаемой изменчивости объясняемой переменной.
Напротив, в случае, когда Гипотеза ![]() Не отвергается (Вариант 2), говорят, что параметр
Не отвергается (Вариант 2), говорят, что параметр![]() статистически незначим (statistically unsignificant). В этом случае В рамках используемого статистического критерия мы не получаем убедительных аргументов против предположения о том, что
статистически незначим (statistically unsignificant). В этом случае В рамках используемого статистического критерия мы не получаем убедительных аргументов против предположения о том, что![]() . Это соответствует признанию того, что наличие J-Й объясняющей переменной в правой части модели Не существенно для объяснения наблюдаемой изменчивости объясняемой переменной, а следовательно, можно обойтись и Без включения этой переменной в модель регрессии.
. Это соответствует признанию того, что наличие J-Й объясняющей переменной в правой части модели Не существенно для объяснения наблюдаемой изменчивости объясняемой переменной, а следовательно, можно обойтись и Без включения этой переменной в модель регрессии.
Впрочем, выводы о статистической значимости (или незначимости) того или иного параметра модели Зависят от выбранного уровня значимости ![]() : решение в пользу Статистической значимости параметра может измениться на противоположное При уменьшении
: решение в пользу Статистической значимости параметра может измениться на противоположное При уменьшении ![]() , а решение в пользу Статистической незначимости параметра может измениться на противоположное При уменьшении значения
, а решение в пользу Статистической незначимости параметра может измениться на противоположное При уменьшении значения![]() .
.
Пример. В уже рассматривавшемся выше примере с уровнями безработицы в США получаем в распечатке ![]() и следующую таблицу:
и следующую таблицу:
|
Переменная |
Коэф-т |
Ст. ошибка |
T-статист. |
P-знач. |
|
1 |
2.294 |
0.410 |
5.589 |
0.0001 |
|
ZVET |
0.125 |
0.062 |
2.011 |
0.0626 |
Соответственно, при выборе уровня значимости ![]() коэффициент при переменной
коэффициент при переменной ![]() признается Статистически незначимым (
признается Статистически незначимым (![]() -Значение Больше уровня значимости). Однако, если выбрать
-Значение Больше уровня значимости). Однако, если выбрать![]() , то
, то ![]() -Значение Меньше уровня значимости, и коэффициент при переменной
-Значение Меньше уровня значимости, и коэффициент при переменной ![]() придется признать Статистически значимым.
придется признать Статистически значимым.
Пример. При исследовании зависимости спроса на куриные яйца от цены (данные были приведены ранее) получаем в распечатке ![]() и следующую таблицу:
и следующую таблицу:
|
Переменная |
Коэф-т |
Ст. ошибка |
T-статист. |
P-знач. |
|
1 |
21.100 |
2.304 |
9.158 |
0.0000 |
|
CENA |
–18.559 |
5.010 |
-3.705 |
0.0026 |
Здесь коэффициент при объясняющей переменной ![]() Статистически значим даже при выборе
Статистически значим даже при выборе![]() , так что цена является Существенной объясняющей переменной.
, так что цена является Существенной объясняющей переменной.
Пример. Регрессионный анализ потребления свинины на душу населения США в зависимости от оптовых цен на свинину (данные были приведены ранее) дает значения ![]() и
и
|
Переменная |
Коэф-т |
Ст. ошибка |
T-статист. |
P-знач. |
|
1 |
77.484 |
13.921 |
5.566 |
0.0001 |
|
Цена |
-24.775 |
29.794 |
-0.832 |
0.4219 |
В этом примере коэффициент при переменной Цена Оказывается Статистически незначимым при Любом разумном выборе уровня значимости ![]() .
.
Замечание. Мы уже отмечали ранее возможность Ложной Корреляции между двумя переменными и, соответственно, возможность Ложного использования Одной из переменных в качестве объясняющей для описания изменчивости другой переменной. Проиллюстрируем такую ситуацию на основе рассмотренных нами методов регрессионного анализа.
Пример. В числе прочих подобных примеров мы получили модель линейной связи между мировым рекордом по прыжкам в высоту с шестом среди мужчин (![]() , в См) и суммарным производством электроэнергии в США (
, в См) и суммарным производством электроэнергии в США (![]() , В Млрд. квт-час). Мы уже указывали на высокое значение коэффициента детерминации для этой модели:
, В Млрд. квт-час). Мы уже указывали на высокое значение коэффициента детерминации для этой модели: ![]() . Теперь мы можем привести результаты регрессионного анализа:
. Теперь мы можем привести результаты регрессионного анализа:
|
Переменная |
Коэф-т |
Ст. ошибка |
T-статист. |
P-знач. |
|
1 |
-2625.497 |
420.840 |
-6.234 |
0.0000 |
|
H |
7.131 |
0.841 |
8.483 |
0.0000 |
Формально, переменная ![]() признается Существенной для объяснения изменчивости переменной
признается Существенной для объяснения изменчивости переменной ![]() , так что здесь мы сталкиваемся с Ложной (Паразитной) регрессией переменной
, так что здесь мы сталкиваемся с Ложной (Паразитной) регрессией переменной ![]() на переменную
на переменную ![]() , обусловленной наличием выраженного (линейного) тренда обеих переменных во времени.
, обусловленной наличием выраженного (линейного) тренда обеих переменных во времени.
| < Предыдущая | Следующая > |
|---|