2.06. Доверительные интервалы для . коэффициентов: реальные . статистические данные
Итак, практическому построению доверительных интервалов для коэффициентов ![]() нормальной модели линейной множественной регрессии
нормальной модели линейной множественной регрессии
![]()
С ![]() ~ I. i. d.
~ I. i. d. ![]() препятствует вхождение в выражения для дисперсий
препятствует вхождение в выражения для дисперсий
![]()
Неизвестного Значения S 2.
Единственный выход из этого положения — Заменить неизвестное значение S 2 Какой-нибудь подходящей его Оценкой (Estimate), которую можно было бы Вычислить на основании имеющихся статистических данных. Такого рода оценки принято называть Статистиками (Statistics).
В данной ситуации такой подходящей оценкой для неизвестного значения ![]() Является статистика
Является статистика
![]()
Поскольку сумма ![]() является Квадратичной функцией от случайных величин
является Квадратичной функцией от случайных величин ![]() , то она является случайной величиной, а следовательно, Случайной величиной Является и Статистика S2. Математическое ожидание этой случайной величины равно
, то она является случайной величиной, а следовательно, Случайной величиной Является и Статистика S2. Математическое ожидание этой случайной величины равно ![]() :
:
![]()
Т. е. ![]() — Несмещенная оценка Для
— Несмещенная оценка Для ![]() .
.
Замечание. В частном случае ![]() модель наблюдений принимает вид
модель наблюдений принимает вид
![]()
(случайная выборка из распределения N (Q1,S2)). Несмещенной оценкой для ![]() служит
служит
![]()
Оценкой наименьших квадратов для параметра ![]()
![]() Является
Является ![]() , так что
, так что ![]() , и
, и
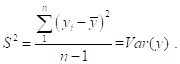
Таким образом, выборочная дисперсия ![]() переменной
переменной ![]() , получаемая делением
, получаемая делением ![]() именно на
именно на ![]() (а не на
(а не на ![]() ), является несмещенной оценкой для
), является несмещенной оценкой для ![]() в модели случайной выборки из нормального распределения, имеющего дисперсию
в модели случайной выборки из нормального распределения, имеющего дисперсию ![]() . Этим и объясняется сделанный нами выбор нормировки при определении выборочных дисперсий и ковариаций.
. Этим и объясняется сделанный нами выбор нормировки при определении выборочных дисперсий и ковариаций.
При выполнении стандартных предположений отношение
![]()
Имеет стандартное распределение, называемое Распределением хи-квадрат с (n-p) степенями свободы. Такое же распределение имеет сумма квадратов ![]() случайных величин, Независимых в совокупности и имеющих одинаковое стандартное нормальное распределение. При
случайных величин, Независимых в совокупности и имеющих одинаковое стандартное нормальное распределение. При ![]() График функции плотности этого распределения имеет вид
График функции плотности этого распределения имеет вид
Для обозначения распределения хи-квадрат с K Степенями свободы используют символ C2(K).
Итак, мы не знаем истинного значения ![]() и поэтому в попытке построить доверительный интервал для
и поэтому в попытке построить доверительный интервал для ![]() вынуждены заменить неизвестное нам значение
вынуждены заменить неизвестное нам значение ![]() На его несмещенную оценку
На его несмещенную оценку
![]()
Соответственно, вместо отношения
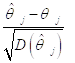
Приходится использовать отношение
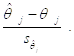
Однако последнее отношение Как случайная величина уже Не имеет стандартного нормального распределения, поскольку в знаменателе теперь стоит не постоянная, а Случайная величина.
Тем не менее, распределение последнего отношения также относят к стандартным, и оно известно под названием T-распределения Стьюдента с (n-p) степенями свободы.
Для распределения Стьюдента с K Степенями свободы принято обозначение T (K). Квантиль уровня Р Такого распределения будем обозначать символом Tp (K). График функции плотности распределения Стьюдента симметричен относительно нуля и похож на график функции плотности нормального распределения. Например, при K=10 он имеет следующий вид (левый график).
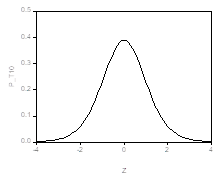
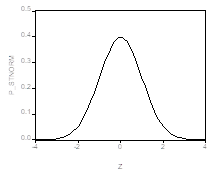
Для сравнения, справа приведен график функции стандартного нормального распределения. Отличие графиков столь невелико, что визуально они почти неразличимы. Квантили этих двух распределений различаются более ощутимо:
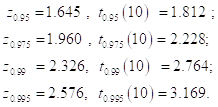
Распределение Стьюдента имеет Более тяжелые хвосты. Из приведенных значений квантилей следует, например, что случайная величина, имеющая стандартное нормальное распределение, может превысить значение 1.645 лишь с вероятностью 0.05. В то же самое время, с такой же вероятностью 0.05 случайная величина, имеющая распределение Стьюдента с 10 степенями свободы, принимает значения, большие, чем 1.812.
Впрочем, для значений ![]() квантили распределения Стьюдента
квантили распределения Стьюдента ![]() практически совпадают с соответствующими квантилями cтандартного нормального распределения
практически совпадают с соответствующими квантилями cтандартного нормального распределения ![]() .
.
Итак,
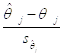 ~
~ ![]() .
.
Поэтому для этой случайной величины выполняется соотношение
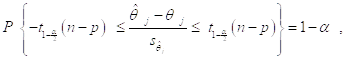
Так что с вероятностью, равной ![]() , выполняется двойное неравенство
, выполняется двойное неравенство
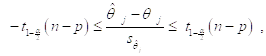
Т. е.
![]()
Иными словами, С вероятностью, равной 1-a, Случайный интервал
![]()
Накрывает истинное значение коэффициента Q j, т. е. является 95%- доверительным интервалом для Q j В случае, Когда не известно истинное значение S 2 Дисперсии случайных ошибок ![]() . В среднем, длина такого интервала больше, чем длина доверительного интервала с тем же уровнем доверия, построенного при Известном значении
. В среднем, длина такого интервала больше, чем длина доверительного интервала с тем же уровнем доверия, построенного при Известном значении ![]() .
.
Замечание. Выбор конкретного значения ![]() определяет компромисс между желанием получить Более короткий доверительный интервал и желанием обеспечить Более высокий уровень доверия.
определяет компромисс между желанием получить Более короткий доверительный интервал и желанием обеспечить Более высокий уровень доверия.
Попытка повысить уровень доверия ![]() , выраженная в выборе Меньшего значения
, выраженная в выборе Меньшего значения ![]() , приводит к квантили
, приводит к квантили![]() с более высоким значением
с более высоким значением ![]() , т. е. к большему значению
, т. е. к большему значению![]() . Но длина доверительного интервала Пропорциональна
. Но длина доверительного интервала Пропорциональна ![]() . Следовательно, Увеличение уровня доверия сопровождается увеличением ширины доверительного интервала (при Тех же статистических данных).
. Следовательно, Увеличение уровня доверия сопровождается увеличением ширины доверительного интервала (при Тех же статистических данных).
Так, для ![]() можно приближенно считать, что
можно приближенно считать, что
![]() ,
,
Где ![]() — квантиль уровня
— квантиль уровня ![]() стандартного нормального распределения. Соответственно, выбирая уровень доверия
стандартного нормального распределения. Соответственно, выбирая уровень доверия ![]() равным
равным ![]() ,
, ![]() или
или ![]() , мы получаем для
, мы получаем для![]() Значения, приблизительно равные
Значения, приблизительно равные ![]() . Это означает, что переход от уровня доверия
. Это означает, что переход от уровня доверия ![]() к уровню доверия
к уровню доверия ![]() сопровождается увеличением длины доверительного интервала приблизительно в
сопровождается увеличением длины доверительного интервала приблизительно в ![]() раза, а дополнительное повышение уровня доверия до
раза, а дополнительное повышение уровня доверия до ![]() увеличивает длину доверительного интервала еще примерно в
увеличивает длину доверительного интервала еще примерно в ![]() раза.
раза.
Теперь мы в состоянии перейти к построению интервальных оценок параметров моделей линейной регрессии для различного рода социально-экономических факторов на основании соответствующих статистических данных.
Пример. Вернемся к модели зависимости уровня безработицы среди белого населения США от уровня безработицы среди цветного населения. Запишем линейную модель наблюдений в виде
![]()
Получаем: ![]()
![]() =
=![]() . Коэффициент
. Коэффициент ![]()
![]() Оценивается величиной
Оценивается величиной ![]() дисперсия
дисперсия ![]() оценивается величиной
оценивается величиной ![]() . Для построения
. Для построения ![]() — Доверительного интервала для
— Доверительного интервала для![]() остается найти квантиль уровня
остается найти квантиль уровня ![]() распределения Стьюдента с
распределения Стьюдента с ![]() степенями свободы. Используя, например, Таблицу А.2 из книги Доугерти (стр.368), находим:
степенями свободы. Используя, например, Таблицу А.2 из книги Доугерти (стр.368), находим: ![]() . Соответственно, получаем
. Соответственно, получаем ![]() -Доверительный интервал для
-Доверительный интервал для![]() в виде
в виде
![]()
Т. е.
![]()
Для ![]() имеем
имеем ![]() ,
, ![]() ;
; ![]() -Доверительный интервал для
-Доверительный интервал для![]() имеет вид
имеет вид
![]()
Т. е.
![]()
В связи с этим примером, отметим два обстоятельства.
(а) Доверительный интервал для коэффициента![]() допускает как Положительные, так и отрицательные значения этого коэффициента.
допускает как Положительные, так и отрицательные значения этого коэффициента.
(б) Каждый из двух построенных интервалов имеет уровень доверия ![]() ; однако это Не означает, что с той же вероятностью
; однако это Не означает, что с той же вероятностью ![]() сразу Оба интервала накрывают истинные значения параметров
сразу Оба интервала накрывают истинные значения параметров ![]() ,
,![]() .
.
Справиться с первым затруднением в данном примере можно, Понизив Уровень доверия до ![]() . В этом случае в выражении для доверительного интервала квантиль
. В этом случае в выражении для доверительного интервала квантиль ![]() заменяется на квантиль
заменяется на квантиль ![]() , так что левая граница доверительного интервала для
, так что левая граница доверительного интервала для![]() Становится положительной и равной
Становится положительной и равной ![]() . Однако это достигается ценой того, что новый доверительный интервал будет накрывать истинное значение параметра
. Однако это достигается ценой того, что новый доверительный интервал будет накрывать истинное значение параметра![]() в среднем только в 90 случаев из 100, а не в 95 из100 случаев.
в среднем только в 90 случаев из 100, а не в 95 из100 случаев.
Что касается второго затруднения, то наиболее простой путь взятия под контроль вероятности Одновременного накрытия доверительными интервалами для![]() ,
,![]() истинных значений этих параметров связан с тем, что
истинных значений этих параметров связан с тем, что
![]() Оба интервала накрывают
Оба интервала накрывают ![]() и
и![]() , соответственно
, соответственно![]() =
=
![]() Хотя бы один из них Не накрывает соответствующее
Хотя бы один из них Не накрывает соответствующее ![]() =
=
![]() Доверительный интервал для
Доверительный интервал для![]() не накрывает
не накрывает![]()
![]() +
+
![]() доверительный интервал для
доверительный интервал для![]() не накрывает
не накрывает![]()
![]() -
-
![]() Оба интервала не накрывают свои
Оба интервала не накрывают свои ![]()
![]() =
=
![]()
![]() Оба интервала не накрывают свои
Оба интервала не накрывают свои![]()
![]() ³
³
![]()
Следовательно, если построить доверительный интервал для![]() и доверительный интервал для
и доверительный интервал для![]() с уровнями доверия каждого, равными
с уровнями доверия каждого, равными ![]() , то тогда правая часть полученной цепочки соотношений будет равна
, то тогда правая часть полученной цепочки соотношений будет равна ![]()
Это означает, что в нашем примере мы можем гарантировать, что вероятность Одновременного накрытия истинных значений![]() ,
,![]() соответствующими доверительными интервалами будет Не менее
соответствующими доверительными интервалами будет Не менее ![]() , если возьмем
, если возьмем ![]() . Но тогда при построении этих интервалов придется использовать вместо значения
. Но тогда при построении этих интервалов придется использовать вместо значения
![]()
Значение
![]() ,
,
Так что каждый из исходных интервалов Увеличится в ![]() раза. Это, конечно, приводит к еще более неопределенным выводам относительно истинных значений параметров
раза. Это, конечно, приводит к еще более неопределенным выводам относительно истинных значений параметров![]() ,
,![]() .
.
| < Предыдущая | Следующая > |
|---|