3.2.3. Многомерный дисперсионный анализ
Многомерный дисперсионный анализ является дальнейшим расширением одномерного дисперсионного анализа (после рассмотренного в разделе 3.2.2 ANOVARM), предназначенным для одновременного анализа сразу нескольких зависимых и независимых переменных. Процесс проведения многомерного анализа аналогичен рассмотренному выше обычному одномерному дисперсионному анализу, за исключением того, что в данном случае в область для зависимых переменных можно поместить сразу несколько переменных, а при интерпретации приходится анализировать сразу несколько различий (во всех зависимых переменных).
Давайте рассмотрим процесс проведения многомерного дисперсионного анализа на примере, аналогичном приведённому в разделе 3.2.1 для обычного одномерного дисперсионного анализа, — но в качестве зависимых переменных мы будем рассматривать не только кратность покупок глазированных сырков, но и частоту покупок. В качестве независимых переменных мы возьмем также две переменные: возраст респондентов и количество членов их семей.
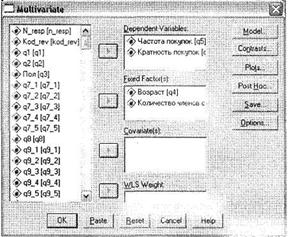
Откройте диалоговое окно Multivariate при помощи меню Analyze ► General Linear Model ► Multivariate. Как вы видите на рис. 3.31, оно аналогично окну Univariate. Поместите две зависимые переменные: q5 (Частота покупок) и q6 (Кратность покупок) в область для зависимых переменных Dependent Variables, а переменные q4 (Возраст) и q72 (Количество членов семьи) — в область для независимых переменных Fixed Factor(s). После этого так же, как для одномерного дисперсионного анализа в окне Post Hoc, задайте вывод тестов Scheffe и Tumhale для обеих независимых переменных, а в окне Options отметьте параметр Homogeneity Tests. После этого можно начать расчеты, щелкнув на кнопке ОК.
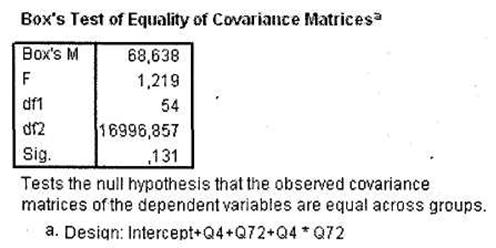
В окне SPSS Viewer появятся результаты многомерного дисперсионного анализа. Первой таблицей, которая должна привлечь ваше внимание, является Box's Test of Equality of Covariance Matrices, представленная на рис. 3.32. В отличие от одномерного дисперсионного анализа с повторяющимися измерениями, здесь тест Box должен быть незначимым (как в нашем случае, Sig. = 0,131), так как неравенство дисперсий исследуемых зависимых переменных в многомерном анализе не является положительным фактом. И напротив, равенство дисперсий зависимых переменных является одним из основных условий проведения многомерного дисперсионного анализа1.
Таблица Multivariate Tests позволяет сделать выводы относительно влияния независимых переменных в отдельности, а также их взаимодействий на зависимые переменные в целом. Поскольку с практической точки зрения влияние не несет никакой смысловой нагрузки, данная таблица обычно не рассматривается.
|
 |
 |
|
Следующей важной таблицей является тест Levene на равенство дисперсий зависимых переменных. Как мы помним из описания одномерного дисперсионного анализа, от факта равенства/неравенства дисперсий в дальнейшем зависит выбор конкретного апостериорного теста: Scheffe или Tumhale. Как вы видите на рис. 3.33, в нашем случае дисперсии равны у обеих зависимых переменных, поэтому далее мы будем опираться на результаты теста Scheffe.
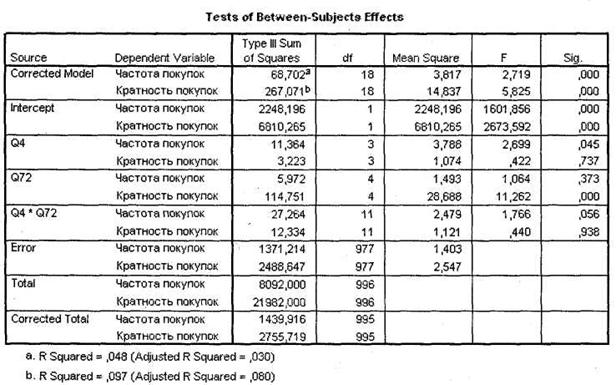
Таблица Tests of Between-Subjects Effects (рис. 3.34) позволяет установить, как каждый эффект влияет на каждую зависимую переменную в отдельности. В отличие от таблицы Multivariate Tests, рассматриваемая таблица позволяет выяснить, на какую конкретно зависимую переменную влияет та или иная независимая переменная и их комбинации. В нашем случае мы видим, что частота покупок определяет различия между категориями переменной q4 Возраст (Sig. = 0,045), а кратность покупок — в категориях переменной q72 Количество членов семьи (Sig. < 0,001).
 |
| |
|
И наконец, последнее, что важно при практической интерпретации результатов многомерного дисперсионного анализа: какие группы каждой из рассматриваемых независимых переменных различаются на основании средних значений зависимых переменных. Это позволяют определить апостериорные тесты (в нашем случае Scheffe). Они рассчитываются для каждой комбинации зависимая переменная/ независимая переменная для всех значений индексов i. Эти таблицы по своему виду аналогичны рассмотренным в предыдущих разделах, посвященных дисперсионному анализу.
Мы не приводим полностью результаты апостериорных тестов из-за их большого объема.
На рис. 3.35 представлены результирующие таблицы Homogenous Subsets, по которым можно сделать выводы относительно различий между отдельными категориями независимых переменных на основании обеих рассматриваемых зависимых переменных. Также в этих таблицах вы видите однородные кластеры респондентов, различающиеся частотой и кратностью покупок глазированных сырков.
 |
|
Итак, в данной главе мы рассмотрели статистические методы, применяемые для анализа различий между целевыми группами респондентов. Несмотря на то что данные методы (особенно обобщенная линейная модель) достаточно сложны для изучения, их применение позволяет поднять аналитическую работу на существенно более высокий уровень.
| < Предыдущая | Следующая > |
|---|