3.2.2. Одномерный дисперсионный анализ с повторными измерениями
Одномерный дисперсионный анализ с повторными измерениями (ANOVARM) является расширением одномерного дисперсионного анализа (ANOVA). Цель его заключается в анализе различий между ответами одних и тех же респондентов на одни и те же вопросы в несколько приемов, то есть в течение ряда дискретных временных промежутков.
В качестве примера можно привести панельные исследования, когда одни и те же респонденты (потребители какого-либо продукта) отвечают на одни и те же вопросы через определенные интервалы времени (скажем, каждый квартал). Одной из основных целей дисперсионного анализа в рассматриваемом случае будет оценка влияния на ответы респондентов временного фактора. Таким образом, в частности, можно установить уровень лояльности к продуктам различных марок: если с течением времени средние оценки продукта марки X существенно не меняются/ возрастают/убывают, следовательно, и отношение респондентов к данной марке сохраняется на прежнем уровне/улучшается/ухудшается. Иными словами, дисперсионный анализ с повторными измерениями может применяться для оценки значимости тенденций.
В маркетинговых исследованиях этот тип статистического анализа находит весьма разнообразные применения. Он может применяться не только в процессе анализа баз данных по маркетинговым исследованиям, но и в процессе сбора анкет — для контроля работы интервьюеров. Например, если опрос производится каждый
День в течение недели в одних и тех же местах, можно анализировать средние значения основных переменных, во-первых, по дням недели, а во-вторых, по каждому интервьюеру. Если будут выявлены существенные различия в анкетах интервьюеров, то высока вероятность фальсификации (тем интервьюером, анкеты которого наиболее сильно отличаются от остальных).
Необходимо сделать важное отступление. Дело в том, что некоторые источники иногда относят анализ с повторными измерениями к одномерному, а иногда — к многомерному дисперсионному анализу. В справочной системе SPSS не указана явно принадлежность ANOVARM к одной или другой группе статистических методов. По сути расчетов ANOVARM близок к многомерному дисперсионному анализу, поскольку в качестве зависимой переменной выступают сразу несколько переменных, кодирующих ряд временных периодов. Но так как основная задача данного пособия — объяснение практических приемов работы с SPSS для эффективного применения этого программного продукта в маркетинговых исследованиях, мы отдаем предпочтение семантическому толкованию статистических терминов. Зависимые переменные в ANOVARM по смыслу (с точки зрения исследователя) представляют собой фактически одну и ту же переменную, только измеренную многократно. В этой трактовке следует скорее говорить о специфической форме одномерного дисперсионного анализа, в котором зависимая переменная представлена набором подпеременных (точно так же, как при кодировании многовариантных вопросов; см. раздел 1.4.2). Таким образом, мы придерживаемся точки зрения тех авторов, которые считают ANOVARM видом одномерного дисперсионного анализа (ANOVA).
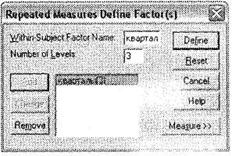
Итак, в качестве иллюстрации использования одномерного дисперсионного анализа с повторяющимися измерениями рассмотрим следующий пример. Проводится исследование мнений респондентов относительно одежды марки X. Одним из вопросов анкеты является следующий: Поставьте оценку одежды марки X по пятибалльной шкале (от 1 — очень плохо до 5 — отлично). Респонденты разделяются на группы по полу и возрасту. Исследование проводится с частотой раз в квартал в течение года. В результате в итоговой базе данных получены три переменные: ql8, ql9 и q20, отражающие уровень оценки респондентами одежды марки X в первом, втором и третьем кварталах, а также две переменные, указывающие пол (q80) и возраст (q74) опрошенных. Требуется установить, как меняется общая картина восприятия респондентами одежды марки X в течение одного года. Поставленная задача легко решается методом одномерного дисперсионного анализа с повторяющимися измерениями. Откройте диалоговое окно Repeated Measures Define Factor(s) при помощи меню Analyze ► General Linear Model ► Repeated Measures (рис. 3.24). Это диалоговое окно предназначено для формирования временных факторов, то есть определения составных переменных, описывающих эти факторы. У нас есть три временных интервала (квартала), поэтому в поле Within-Subject Factor Name напишите название этой составной переменной: кварталы, а в поле Number of Levels — число временных периодов, когда производились измерения (3 квартала). После этого щелкните на кнопке Add, чтобы добавить новую составную переменную в список. Таким способом можно задать сразу несколько составных временных переменных, однако в маркетинговых ис
 |
следованиях в большинстве случаев ограничиваются только одной.
|
Кнопка Measure служит для задания дополнительных измерений временных переменных, но в маркетинговых исследованиях эта функция обычно не используется.
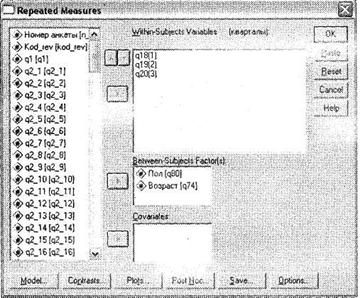 |
Щелкните на кнопке Define, и откроется новое диалоговое окно Repeated Measures (рис. 3.25), похожее (как по внешнему виду, так и по своим функциям) на окно Univariate. В этом окне в левом списке всех доступных переменных выберите те, в которых закодированы оценки респондентов в каждый из временных промежутков (в нашем случае — ql8, ql9, q20), и последовательно (то есть в порядке возрастания периодов) перенесите их в область Within-Subjects Variables (кварталы).
|
Теперь в рассматриваемой области определена составная временная переменная, описывающая оценки респондентами одежды марки X в каждый из трех рассматриваемых кварталов. Таким образом, область Within-Subjects Variables (кварталы) является аналогом области Dependent Variable в одномерном дисперсионном анализе, только зависимая переменная в нашем случае как бы распадается на три подпеременные, вместе составляющие одно целое. Далее в область Between-Subjects Factor(s) поместите те переменные, которые служат основаниями для различения оценок. В нашем случае это демографические характеристики респондентов: пол (q80) и возраст (q74).
Итак, вы задали все переменные для исследования и можете использовать кнопки, расположенные в нижней части этого диалогового окна, — так же, как вы делали это при одномерном дисперсионном анализе (см. раздел 3.2.1). В окне Post Нос задайте апостериорные тесты Scheffe (для равных дисперсий) и Tumhale (для неравных дисперсий) для переменных, имеющих более двух категорий (в нашем случае это только q74 — Возраст). В окне Options выберите параметр Homogeneity Tests и в соответствующее поле поместите переменные с двумя категориями, для которых следует рассчитать средние значения (q80 — Пол и все взаимодействия, в которых она участвует). Остальные диалоговые окна аналогичны рассмотренным для одномерного дисперсионного анализа, поэтому мы не приводим их второй раз.
В результате мы выясняем, какой из трех факторов — пол, возраст или время (кварталы) — определяет различия в оценках одежды марки X. Запустив программу на исполнение щелчком на кнопке ОК, в окне SPSS Viewer вы увидите результаты дисперсионного анализа. В целом они аналогичны результатам, отображаемым при одномерном дисперсионном анализе, однако данные результаты значительно обширнее и содержат несколько дополнительных таблиц. Так как настоящее пособие посвящено сугубо практическим задачам использования SPSS в маркетинговых исследованиях, мы рассмотрим только ту часть результатов, которая необходима на практике.
 |
Итак, первое, что должно привлечь ваше внимание, — это таблица Box's Test of Equality of Covariance Matrices (рис. 3.26). Тестовая статистика Box показывает, существуют ли статистически значимые различия в оценках респондентов в каждом из анализируемых периодов. В нашем случае мы видим высокую значимость (Sig. < 0,001), свидетельствующую о том, что оценки респондентами одежды марки X существенно меняются от квартала к кварталу.
|
После анализа результатов теста Box мы смотрим на следующую важную таблицу — Multivariate Tests (рис. 3.27), позволяющую сделать выводы о том, в какой степени выявленные различия определяются влиянием временного фактора, а также взаимодействием этого фактора с другими переменными, включенными
В анализ. Так, в нашем случае мы видим, что непосредственно временной фактор (кварталы) в значительной степени определяет различия в исследуемых оценках (Sig. < 0,001). Сочетание эффектов времени и пола (Кварталы х q80), а также времени и возраста респондентов (Кварталы х q74) с высокой вероятностью определяют различия в оценках одежды (Sig. = 0,002 и 0,024). А вот тройственное взаимодействие всех анализируемых величин в совокупности не оказывает никакого влияния на изучаемую разницу в оценках (Sig. = 0,935). Обратите внимание на то, что при интерпретации таблицы Multivariate Tests следует оценивать значимость того или иного фактора всегда на основании теста Pillai's Trace. Именно этот тест статистической значимости является наиболее надежным (робастп-ным).
|
 |
Мы ответили на два основных вопроса:
1. изменяются ли статистически значимо оценки респондентами одежды марки X?
2. чем определяются эти различия: только влиянием временного фактора или также влиянием независимых переменных (пола и возраста)?
В результате анализа мы смогли утвердительно ответить на оба вопроса: различия в оценках есть, и они определяются как временем, так и его взаимодействием с полом и возрастом. Дальнейший анализ будет направлен на исследование влияния независимых переменных и их взаимодействий по отдельности на оценки респондентов.
Следующие три таблицы: — Mauchly's Test of Sphericity, Tests of Within-Subjects Effects и Tests of Within-Subjects Contrasts — обычно пропускаются, так как они не позволяют сделать никаких новых выводов и лишь подтверждают представленные выше результаты. После трех таблиц следуют результаты одномерного дисперсионного анализа для независимых переменных, для которых не производятся повторные измерения, знакомые вам по разделу 3.2.1.
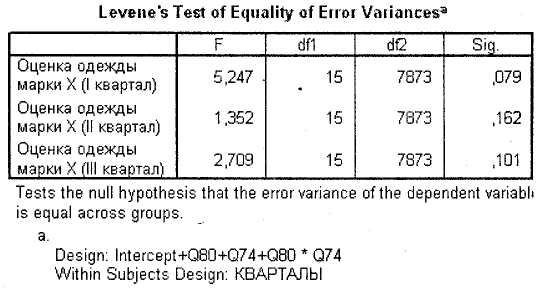
Таблица Levene's Tests of Equality of Error Variances (рис. 3.28) позволяет определить однородность дисперсий в каждый из исследуемых промежутков времени. Так, в нашем случае мы видим, что во всех трех исследуемых кварталах дисперсии однородны (Sig. > 0,05).
|
 |

Из таблицы Tests of Between-Subjects Effects (рис. 3.29) мы видим, что и пол, и возраст респондентов с весьма высокой вероятностью определяют различия в оценках одежды марки X (Sig. < 0,001), а вот их взаимодействие — нет (Sig. = 0,058).
|
Теперь нам осталось определить, как именно различаются оценки под влиянием выявленных значимых факторов и их взаимодействий. Во-первых, мы определи-
Ли, что на различии в оценках респондентов в каждый из трех анализируемых периодов оказывают влияние пяти эффектов:
■ временной фактор (кварталы);
■ взаимодействие времени с полом;
■ взаимодействие времени с возрастом;
■ пол;
■ возраст.
К сожалению, провести апостериорные тесты для временной переменной SPSS не позволяет, поэтому при определении различий между группами временной переменной приходится ориентироваться исключительно на средние значения (оценки). Возраст является единственной переменной, для которой можно провести стандартные апостериорные тесты (см. далее). Для остальных значимых взаимодействий выводятся средние значения: оценки одежды марки X в каждой рассматриваемой категории респондентов (см. рис. 3.28). Кроме таблиц для данных взаимодействий целесообразно вывести и графики. Это облегчит интерпретацию и позволит наглядно определить различия между категориями респондентов.
|
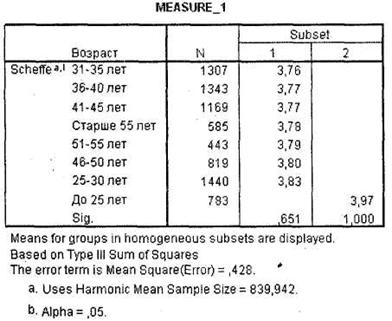 |
Завершают вывод результатов одномерного дисперсионного анализа с повторяющимися измерениями таблицы апостериорных тестов для переменных с числом категорий более двух1. В нашем случае это две таблицы для переменной Возраст: Multiple Comparisons и Homogeneous Subsets. Первую таблицу мы не приводим из-за ее большого размера, вместо этого приведена дублирующая ее вторая таблица, показывающая однородные группы респондентов по оценкам одежды марки X
(рис. 3.30). Из таблицы вы видите, что наивысший уровень оценок достигается в возрастной группе респондентов (в среднем 4,0 балла) младше 25 лет. Респонденты старше 25 лет склонны оценивать одежду марки X несколько ниже (в среднем на 3,8 балла).
| < Предыдущая | Следующая > |
|---|