2.2. Линейные распределения для многовариантных вопросов
Как было сказано выше (см. раздел 1.4.2), в SPSS все многовариантные вопросы рассматриваются как совокупность одновариантных переменных, обозначающий варианты ответа. Иными словами, многовариантный вопрос, содержащий три варианта ответа, в SPSS представляется как три дихотомические переменные, принимающие два значения-флага: отмечено/не отмечено.
Наиболее распространены два формата представления многовариантных переменных. В первом случае переменные, представляющие варианты ответа многовариантной переменной, принимают значение 1 (выбрано) или 0 (не выбрано); во втором случае — 1 (выбрано) или System Missing (не выбрано).
Как показывает опыт, первый способ предпочтительнее. Второй способ используется в специфических случаях (например, если необходимо использовать SPSS в качестве клиента автоматизации построения распределений при помощи программ на Sax Basic). Чтобы указать SPSS, какие переменные являются вариантами ответа для многовариантной переменной, наиболее часто используется описываемый далее способ, при котором после формирования многовариантной переменной ее можно использовать для построения линейных и перекрестных распределений.
Для иллюстрации мы построим линейное распределение по многовариантному вопросу Где Вы покупаете сметану? (q7) с вариантами ответа:
1. продмаг (q7_l);
2. рынок (q7_2);
3. супермаркет (q7_3);
4. палатка (q7_4);
5. универсам (q7_5).
Чтобы построить распределения по многовариантным вопросам, прежде всего необходимо сформировать многовариантную переменную. Это делается при помощи меню Analyze ► Multiple Response ► Define Sets. Открывшееся диалоговое окно позволяет сформировать многовариантные переменные (правый список) из общего списка доступных переменных (левый список), как показано на рис. 2.10.
 |
|
Для создания многовариантной переменной, обозначающей типы торговых точек, сначала выберите в левом списке все дихотомические переменные, кодирующие множественные варианты ответов (q7_l — q7_5), и переместите их в правый список. Далее в области Variables Are Coded As оставьте выбранный по умолчанию параметр Dichotomies (он указывает, что переменные, обозначающие варианты ответа в многовариантном вопросе, являются дихотомическими) и в соответствующее поле введите цифру, указывающую, что вариант ответа выбран (в нашем случае 1). В поле Name введите имя для вновь создаваемой многовариантной переменной. Назовите ее q7 и присвойте метку Торговые точки (в поле Label). Затем, чтобы создать новую переменную, щелкните на кнопке Add. Обратите внимание, что к именам создаваемых многовариантных переменных добавляется префикс $ (этим они отличаются от обычных одновариантных переменных). Теперь вы можете создать еще одну или несколько многовариантных переменных, добавляя их в соответствующий список при помощи кнопки Add. Так как в нашем случае мы собираемся анализировать только один многовариантный вопрос, завершим процесс создания новых переменных щелчком на кнопке Close.
Необходимо отметить, что SPSS не сохраняет многовариантные переменные при закрытии рабочего файла с данными. Поэтому каждый раз, когда нужно проанализировать многовариантные вопросы, вам придется снова создавать соответствующие переменные.
Мы создали многовариантную переменную для анализа и теперь можем приступать к построению линейных распределений. Для этого воспользуемся меню Analyze ► Multiple Response ► Frequencies. Следует отметить, что данное меню позволяет строить только таблицы линейных распределений (и нет возможности вывести диаграммы). В открывшемся диалоговом окне в левом списке всех доступных многовариантных переменных (в нашем случае там только одна переменная Торговые точки) выберите интересующие переменные для анализа и перенесите их в правую область Table(s) for (рис. 2.11). Для того чтобы запустить процедуру построения линейных распределений, щелкните на кнопке ОК.
|
 |
В окне SPSS Viewer будет создана таблица с линейными распределениями (частотами) по выбранным переменным (рис. 2.12). Столбец Count содержит количество респондентов, указавших каждый из возможных вариантов ответа на многовариантный вопрос. Столбец Pet of Cases показывает доли каждого варианта ответа от общего числа респондентов, ответивших на многовариантный вопрос (гистограмма). Данное число показано под таблицей (999 valid cases, то есть линейное распределение построено по 999 респондентам) и рассчитано как количество анкет, в которых выбран хотя бы один из возможных вариантов ответа на данный многовариантный вопрос. В той же строке (под таблицей) указано количество анкет, в которых не выбрано ни одного варианта ответа (4 missing cases, то есть четыре респондента не указали, в каких типах торговых точек они обычно приобретают сметану). Столбец Pet of Responses показывает доли каждого варианта ответа от общего числа ответов; их сумма всегда равна 100 % (сектограмма). Суммы по каждому столбцу анализируемой таблицы представлены в строке Total responses.
|
Pet of |
Pet of | |||
|
Dichotomy label |
Name |
Count |
Responses |
Cases |
|
Продмаг |
Q7_l |
518 |
39,4 |
SI,9 |
|
Рынок |
Q7_2 |
306 |
23,3 |
30,6 |
|
Супермаркет |
Q7_3 |
258 |
19,6 |
25,8 |
|
Палатка |
Q7_4 |
166 |
12,6 |
16,6 |
|
Универсам |
Q7_5 |
66 |
5,0 |
6,6 |
|
------ |
----------- |
----------- | ||
|
Total responses |
314 |
100,0 |
131,5 | |
|
4 missing cases; 999 valid cases |
|
В связи с тем, что линейные распределения по многовариантным вопросам в SPSS выводятся в текстовом формате (Plain text) и не могут быть перенесены в Microsoft Excel для построения диаграмм, далее мы рассмотрим, как можно строить диаграммы по многовариантным вопросам непосредственно в SPSS.
Если вам необходимо построить гистограмму или сектограмму по многовариантному вопросу, меню Define Sets не используется. Вместо него применяется меню Graphs ► Bar (для гистограмм) или Graphs ► Pie (для сектограмм). За один раз можно построить гистограмму или сектограмму только по одной многовариантной переменной.
Итак, давайте построим гистограмму по многовариантной переменной Торговые точки (параллельно мы построим и сектограмму). Для этого воспользуемся меню Graphs ► Bar. В открывшемся диалоговом окне (рис. 2.13) необходимо указать тип гистограммы Simple (если мы строим сектограмму, данный пункт отсутствует; см. рис. 2.14), а в группе Data in Chart Are выбрать пункт Summaries of separate variables. Затем необходимо щелкнуть на кнопке Define, чтобы перейти к следующему шагу построения диаграммы.
 |
|
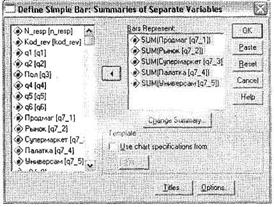
В открывшемся диалоговом окне Summaries of Separate Variables (оно одинаково и для гистограмм и для сектограмм) из левого списка всех доступных переменных, имеющихся в файле данных, переместите в правый список все варианты ответа на какой-либо один многовариантный вопрос (в нашем случае это переменные q7_l — q7_5). как видно на рис. 2.15.
|
 |
 |
|
 |
|
 |
|
 |
|
Щелкните на кнопке Change Summary и в открывшемся диалоговом окне (рис. 2.16) выберите пункт Sum of values. Данный параметр указывает SPSS на необходимость построить гистограмму по суммарному количеству выбранных вариантов ответа в многовариантном вопросе. После этого закройте данное окно, щелкнув на кнопке Continue.
Теперь щелкните на кнопке Options и в открывшемся окне выберите пункт Exclude cases variable by variable; щелкните на Continue (рис. 2.17).
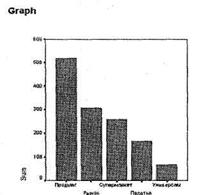
Щелкните на кнопке ОК в главном диалоговом окне Summaries of Separate Variables, и программа выведет результаты построения гистограммы в окне SPSS Viewer (рис. 2.18).
Как видите, столбцы построенной гистограммы отражают абсолютное количество респондентов, указавших ту или иную торговую точку. К сожалению, SPSS не позволяет строить гистограмму по многовариантным вопросам, отражающую проценты каждого варианта ответа от общего числа респондентов (или от общего числа ответов). Чтобы отобразить на нашей гистограмме точные количества респондентов, указавших ту или иную торговую точку, следует воспользоваться схемой действий, представленной выше.
Мы рассмотрели наиболее популярный метод статистического анализа данных в маркетинговых исследованиях — построение линейных распределений. Как показывает практика, именно на этом этапе в некоторых отечественных компаниях заканчивается работа с SPSS (иногда строятся также перекрестные распределения), в то время как описательный анализ является лишь начальным этапом анализа данных.
| < Предыдущая | Следующая > |
|---|