17. Выборочный метод. Корреляционные связи
Для проведения статистических наблюдений и построения соответствующих распределений вначале важно выделить полное множество объектов, обладающих данным признаком. Это множество называют Генеральной совокупностью. Как правило, генеральная совокупность содержит огромное (теоретически бесконечное) число элементов, поэтому наблюдение не в состоянии охватить всю совокупность и становится возможным только выборочное наблюдение. Часть единиц генеральной совокупности, подлежащая непосредственному наблюдению, называют выборочной совокупностью или Выборкой.
Математическая статистика занимается определением свойств генеральной совокупности по свойствам выборки.
Так, экспериментальные распределения, вследствие своей ограниченности по сравнению с теоретическими распределениями, могут служить примером выборки случайных величин, которая характеризуется определенным уровнем доверительности. Вообще говоря, любая экспериментальная выборка репрезентативна (представительна) лишь в той или иной степени. Согласно теореме Ляпунова, при достаточно большом числе независимых наблюдений в генеральной совокупности с конечной средней и ограниченной дисперсией, вероятность того, что расхождение между выборочной и генеральной средней, не превзойдет по модулю величину произведения Tμ , равна интегралу Лапласа Ф(T), рассчитанному в пределах от – T до + T (При μ2 = <σ2Выб>). Обозначая выборочную среднюю <Хвыб>,а генеральную (теоретическую) среднюю Хср,имеем:
Р(|<хвыб>–хср| ≤ Tμ)=Ф(T).
Численное значение интеграла Лапласа
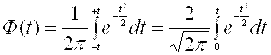
Можно найти в справочниках по математике.
Доверительный интервал для генеральной средней заключен в пределах ±Tμ. Величину T называют коэффициентом доверия. При T=1,96 доверительная вероятность равна 0,95 (95%), а при T=2,58 - 0,99 (99%).
Репрезентативность выборки из N величин генеральной совокупности была исследована Стьюдентом. Рассмотрим конкретный пример.
При проведении социально-экономических исследований по определению среднего уровня оплаты труда категории работников коммерческих банков было выяснено, что в выбранном регионе разница между наибольшим и наименьшим уровнем оплаты операционистов оказалась равной 3 тыс. руб. Если считать, что эта величина соответствует разбросу 6σ (от –3σ до +3σ), то оценка величины стандартного отклонения, судя по выборке, составляет 3000 руб./ 6 =500 руб. Для дальнейших расчетов, зададимся предельной ошибкой выборки в 100 руб. Обозначим эту величину Δ. С другой стороны, Δ не превосходит величины доверительного интервала Tμ, где μ2=σ2ср; σ2Ср = σ2 /N, а N – размер выборки (количество обследованных операционалистов). Тогда можно записать:
Δ = Tμ = 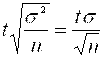 . Откуда получаем, что
. Откуда получаем, что 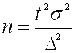 . После подстановки данных, имеем:
. После подстановки данных, имеем: 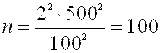 . Итак, необходима выборка из 100 человек. Подстановка величины T = 2 означает, что результат получен с уверенностью 95,4%.
. Итак, необходима выборка из 100 человек. Подстановка величины T = 2 означает, что результат получен с уверенностью 95,4%.
Согласие между теорией и экспериментом можно оценить количественно, если отнестись к экспериментальным данным и теоретическим переменным в распределении как к системе, содержащей наборы из двух независимых величин. Критерий согласия между ними был предложен Пирсоном (χ2 - критерий) и рассчитывается по отклонению экспериментальных частот от вероятностей теоретического распределения для одинаковых интервалов СВ.
Для проведения расчетов необходимо:
· произвести с экспериментальными данными процедуру центрирования и нормирования, т. е. перейти к новым переменным  Для каждого интервала затем необходимо вычислить TН(хН) и TВ(хВ). Эти значения будут опорными для перехода к теоретическому распределению;
Для каждого интервала затем необходимо вычислить TН(хН) и TВ(хВ). Эти значения будут опорными для перехода к теоретическому распределению;
· найти по таблицам величины интегралов ![]() и
и ![]() , что геометрически представляет собой площади под теоретической кривой распределения F(X) в пределах от – ∞ до правых границ, соответственно, TН и TВ ;
, что геометрически представляет собой площади под теоретической кривой распределения F(X) в пределах от – ∞ до правых границ, соответственно, TН и TВ ;
· рассчитать для каждого I-го интервала вероятность РI = F1(x) – F2(x) попадания СВ между TiВ и TiН ;
· рассчитать абсолютную частоту (Mi или Fi) появления СВ в каждом интервале умножением соответствующей вероятности РI на общее количество N – значений случайной величины. Действительно, по частотному определению вероятности РI = Mi/N = Fi/N ;
· вычислить критерий Пирсона по формуле:
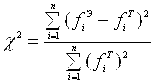 , где верхние индексы частот относятся либо к экспериментальному (Э), либо к теоретическому (Т) распределениям.
, где верхние индексы частот относятся либо к экспериментальному (Э), либо к теоретическому (Т) распределениям.
Этапы подготовки экспериментальных данных для расчета критерия согласия представлены на конкретном примере в табл. 5.9, 5.11 (Приложение II ). Нумерация таблиц и другая информация в Приложении II взята в соответствии с первоисточником из учебника по Общей теории статистики [1]. В математических справочниках имеются таблицы значений критерия согласия, вычисленные в зависимости от числа степеней свободы (эта характеристика определяется как количество интервалов k –3) и уровня значимости, обозначаемого α. Если α = 0,005, то это означает 0,5-процентную ошибку или 99,5%-ю уверенность в результатах анализа. Так например, для данных, приведенных в табл.5.9 вычисленная величина χ2 – критерия оказалась близкой к 4, а табличное значение критерия при α = 0,005 и числе степеней свободы k–3=4 составляет 9,5. Поэтому гипотеза о нормальности полученного экспериментально распределения оправдывается с 99%-й уверенностью. Еще одно уточнение связано с тем, что критерий Пирсона хорошо «работает» при достаточно большом наборе экспериментальных данных (N ≥ 50) и частотах в различных интервалах не меньше 5. В соответствии с этими рекомендациями количество интервалов K В рассматриваемом примере оказалось равным 7, а число степеней свободы 4.
Согласование в системе из двух наборов случайных величин {Xi} и {Yj} может быть обнаружено в рамках корреляционного анализа, в основе которого лежит гипотеза о связи между двумя признаками. Один из признаков – факторный (условно, определяющий), а другой – результативный. Рассмотрим процедуру поиска корреляционной связи на конкретном примере. Табл.7.1, 7.3 (Приложение) задают два набора СВ: сгруппированные данные по затратам фирм на рекламу {xi} и среднее количество туристов в году {yj}, воспользовавшихся услугами этих групп фирм (всего 20 пар значений). Диаграмма, изображенная на рис.7.1 (Приложение) представляет эти данные в корреляционном поле величин X И Y. Усредняя данные по величинам Y для различных фирм, затративших на рекламу одинаковые средства Х, можно построить эмпирическую линию связи между Х и Y (так называемую, линию регрессии), подобрать теоретические коэффициенты линии связи и убедиться в наличии зависимости числа клиентов фирм от затрат на рекламу.
Можно также рассчитать для нормированных значений ![]() и
и ![]() среднее нормированное отклонение произведения этих величин с помощью коэффициента Пирсона – линейной корреляции Rxy :
среднее нормированное отклонение произведения этих величин с помощью коэффициента Пирсона – линейной корреляции Rxy :  .
.
В рассматриваемом примере величина коэффициента линейной корреляции, равная Rxy = 0,8105, свидетельствует о возможном наличии прямой корреляционной связи между факторным и результативным признаками. При величине Rxy ,близкой к 0 такая связь не проявляется. Существуют и другие способы оценки связи между случайными величинами.
В том случае, когда исследуемые признаки не имеют количественной меры, может быть использовано экспертное ранжирование. Табл.7.7 (Приложение) представляет сравнительные данные по экспертной оценке рангов кандидатов в депутаты и по количеству поданных за каждого из них голосов избирателей на выборах. Исходя из дисперсии величины разности между рангами х и у, то есть из формулы: 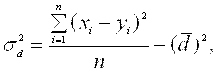 где величина
где величина ![]() а величина N – количество рангов (степеней свободы), Спирмэн получил окончательную формулу для коэффициента ранговой корреляции в виде:
а величина N – количество рангов (степеней свободы), Спирмэн получил окончательную формулу для коэффициента ранговой корреляции в виде:
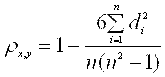 .
.
В рассматриваемом примере коэффициент ранговой корреляции оказался равным 0,758. Так как значения ρ заключены в пределах от –1 до +1, то в данном случае можно предположить наличие прямой зависимости между оценками экспертов и результатами выборов. Однако, при таком небольшом объеме выборки (мало степеней свободы) согласие между величинами Х и У можно утверждать только не более чем с 95%-й уверенностью, так как соответствующее табличное значение ρ (см. справочники по математической статистике) равно 0,636. В то же время, при 99%-й уверенности ρтеор = 0,7818, что больше полученного в эксперименте коэффициента Спирмэна и, следовательно, корреляция между рангами может оказаться случайным совпадением.
Исследования изменений статистических показателей с течением времени приводят к статистическим закономерностям, выраженным в виде Рядов динамики. Так, например, результатом таких исследований, проведенных органами статистики, явилась табл. 8.4 (Приложение), касающаяся динамики среднемесячной заработной платы в России за 1995 год. Проведение подобных исследований за последующие годы может определить тенденцию развития страны. Аналогично, можно использовать ряды динамики не только в макроэкономике, но и по отношению к небольшим предприятиям и организациям. На рис.8.4 представлен ряд динамики выпуска продукции (в денежном выражении) некоторым предприятием. Скачкообразный характер распределения переменной (млн. руб.) во времени не позволяет сразу оценить тенденцию развития предприятия. Для определения закономерности в работе (стабильности, повышения или снижения показателей, ритмичности и т. п.) используется Метод выравнивания ряда динамики, основанный на усреднении данных по укрупненным интервалам. Действительно, так как среднее значение СВ всегда находится между максимальным и минимальным ее значением, то ряд, построенный по средним значениям в укрупненных интервалах, будет характеризоваться меньшими отклонениями (флуктуациями) признака. Процедура выравнивания продемонстрирована на том же графике для укрупненных 3-х дневных и 5-ти дневных скользящих средних. Скользящими они называются потому, что интервалы перекрываются и сдвигаются на один день. При этом количество интервалов не уменьшается по сравнению с исходным графиком.
Еще один пример приведен на рис.8.8 (Приложение), касающийся товарооборота специализированного магазина одной зарубежной фирмы за 1991 – 1995 годы. На диаграмме видно, что скользящая квартальная средняя ведет себя периодически и имеет среднюю линию развития (линию тренда). Следовательно, товарооборот магазина в среднем растет Линейно с течением времени. Скорость роста характеризуется коэффициентом роста K = 0,158, то есть тангенсом угла наклона линии тренда к оси времени.
Очевидно, в реальной жизни встречаются и другие математические функции, описывающие кривую тренда рядов динамики, а подобный анализ поведения систем во времени может быть использован не только в экономике, но и в психологии, педагогике, естествознании, социологии, политике и других сферах человеческой деятельности. Соответственно, можно говорить об экономической, естественнонаучной, педагогической, психологической социальной и др. статистике.
Тема 5. Индексный метод в исследовании социально-экономических явлений. Социальная статистика.
Статистические индексы используются для сопоставления показателей в экономике, при мониторинге деловой либо любой другой активности, при определении уровня жизни и в этом смысле, рассматриваемая тема является в основном социальной. Индекс является относительной величиной, полученной при сопоставлении тех или иных социально-экономических показателей во времени, в группе организаций или систем, а также при прогнозировании и планировании.
В экономике, где индексный метод получил наибольшее распространение, чаще других используют индексы цен (Ip) и индексы физических объемов продукции (Iq):
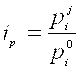 и
и  , где величины
, где величины ![]() и
и ![]() характеризуют,
характеризуют,
Соответственно, цены и количество I-го вида товара, включая акции и другие ценные бумаги, за отчетный J-й период, а 0-й период выбран в качестве базисного. Эти индексы называются Индивидуальными. Использование индивидуальных индексов не всегда удобно, так как на предприятии могут выпускать различные виды товаров, несоизмеримые по цене и по количеству (кнопки и автомобили, например). Единой меркой для них может служить произведение цены товара на его количество. В этом случае мы приходим к так называемым Агрегатным индексам цен и физических объемов:
 ;
;  (формулы Ласпейреса).
(формулы Ласпейреса).
Расчеты основываются на ценах и количестве товаров некоторого периода, взятого за базисный. Возможны и другие подходы.
С помощью индексов фиксируется состояние рынка ценных бумаг(акции, облигации, опционы и др.). Можно выделить интегральные и частные индексы. Так, например, сводный индекс Доу-Джонса рассчитывается по акциям 30 крупнейших промышленных корпораций, 20 транспортных и 15 коммунальных и является интегральным, но он может быть дополнен расчетом частных индексов по отдельным промышленным компаниям.
Важную роль при выборе экономических решений в государстве играет величина индекса потребительских цен, называемый иногда индексом стоимости жизни. Формула его расчета приводится ниже:
 ,
,
Где Ipij- индивидуальный индекс цен I-го товара на J-й территории;
![]() - численность населения J-й территории;
- численность населения J-й территории;
K – число территориальных единиц.
С 1992 года потребительская корзина в России, используемая для расчета индекса потребительских цен, охватывает 409 групп товаров, в том числе 103 позиции продовольственных, 222 – непродовольственных товаров и 84 позиции платных услуг. Так, например, в 1994 году наблюдение проводилось в 834 городах Российской Федерации (данные приведены по учебнику [3]. Таблица 9.10 (Приложение) приводит данные индексов цен за июнь 1994 года, отнесенных к декабрю 1993 года, откуда видно, что это отношение, усредненное по всем потребительским товарам составляет величину 1,75, а следовательно, цены за этот период возросли на 75%. Таким образом фиксируется уровень инфляции.
| < Предыдущая | Следующая > |
|---|