3.3. Неадекватность подобранной модели: примеры и последствия
Пример. Рассмотрим статистические данные по США за период с 1959 по 1985 г. г. о следующих макроэкономических показателях:
DPI — Годовой совокупный располагаемый личный доход;
CONS — Годовые совокупные потребительские расходы;
ASSETS — Финансовые активы на конец календарного года
(все показатели в млрд. долларов, в ценах 1982 г.).
Представление об изменении этих макроэкономических показателей дает следующий график:

Рассмотрим модель наблюдений
![]()
Где индексу T Соответствует (1958+ T) год. Это модель с 3 объясняющими переменными:
![]()
Символ ![]() обозначает переменную, значения которой Запаздывают на одну единицу времени Относительно значений переменной
обозначает переменную, значения которой Запаздывают на одну единицу времени Относительно значений переменной ![]() .
.
Оценивание этой модели дает следующие результаты: ![]() ,
,
![]()
![]()
Объясняющие переменные ![]() имеют высокую статистическую значимость. Ниже представлены Диаграмма рассеяния для предсказанных (CONSF) и наблюдаемых (CONS) значений переменной
имеют высокую статистическую значимость. Ниже представлены Диаграмма рассеяния для предсказанных (CONSF) и наблюдаемых (CONS) значений переменной ![]() , а также График зависимости стандартизованных остатков
, а также График зависимости стандартизованных остатков ![]() (RESID_STAND) от предсказанных (CONSF) значений переменной
(RESID_STAND) от предсказанных (CONSF) значений переменной ![]() :
:


Левый график отражает высокое значение коэффициента детерминации. На правом графике заметно возрастание разброса точек относительно нулевого уровня при значениях ![]()
![]() .
.
Поскольку первый из приведенных в этом примере графиков указывает на возрастание годовых потребительских расходов С течением времени, для реализации процедуры Goldfeld-Quandt Естественно воспользоваться уже имеющимся упорядочением наблюдений во времени (это и будет направлением ожидаемого возрастания дисперсий случайных ошибок). Заметим теперь, что вследствие использования статистических данных, начиная с 1959 года, мы не имеем в своем распоряжении значения ![]() , соответствующего 1958 году. Поэтому реально при оценивании коэффициентов модели наблюдений мы используем Только 26 (а не 27) наборов значений
, соответствующего 1958 году. Поэтому реально при оценивании коэффициентов модели наблюдений мы используем Только 26 (а не 27) наборов значений ![]() ,
, ![]() .
.
Выделим из этих 26 наблюдений две группы, состоящие из первых 10 и последних 10 наборов значений ![]() , соответствующие периодам с 1960 по 1969 и с 1976 по 1985 годы (так что отброшены
, соответствующие периодам с 1960 по 1969 и с 1976 по 1985 годы (так что отброшены ![]() центральных наблюдений). При раздельном подборе линейной модели по этим группам наблюдений получаем остаточные суммы квадратов
центральных наблюдений). При раздельном подборе линейной модели по этим группам наблюдений получаем остаточные суммы квадратов ![]() и
и ![]() , соответственно, так что Наблюдаемое значение
, соответственно, так что Наблюдаемое значение ![]() - статистики критерия Goldfeld-Quandt Равно
- статистики критерия Goldfeld-Quandt Равно
![]()
Если стандартные предположения о случайных ошибках в модели наблюдений Выполнены, то тогда отношение указанных остаточных сумм квадратов как случайных величин имеет ![]() -распределение Фишера
-распределение Фишера ![]() =
= ![]() . Если мы, как обычно, задаем уровень значимости равным
. Если мы, как обычно, задаем уровень значимости равным ![]() , то соответствующее этому уровню значимости Критическое значение
, то соответствующее этому уровню значимости Критическое значение ![]() -статистики равно
-статистики равно
![]()
Наблюдаемое значение этой статистики ![]() Превышает критическое; поэтому гипотеза выполнения стандартных предположений об ошибках Отклоняется в пользу гипотезы возрастания дисперсий
Превышает критическое; поэтому гипотеза выполнения стандартных предположений об ошибках Отклоняется в пользу гипотезы возрастания дисперсий ![]() с ростом значений
с ростом значений ![]() . Заметим, наконец, что вероятность превышения случайной величиной с распределением
. Заметим, наконец, что вероятность превышения случайной величиной с распределением ![]() Значения
Значения ![]() равна
равна
![]()
Сравним результаты применения критерия Голдфелда-Квандта с результатами, получаемыми при использовании двух вариантов критерия Уайта.
При использовании Первого варианта наблюдаемое значение статистики критерия равно ![]() . Поскольку
. Поскольку ![]() , то число степеней свободы соответствующего распределения хи-квадрат равно
, то число степеней свободы соответствующего распределения хи-квадрат равно ![]() . Вероятность того, что случайная величина, имеющая такое распределение, превысит значение
. Вероятность того, что случайная величина, имеющая такое распределение, превысит значение ![]() , равна
, равна ![]() , так что значение
, так что значение ![]() Меньше критического, а значит, гипотеза однородности дисперсий этим вариантом критерия Уайта Не отвергается.
Меньше критического, а значит, гипотеза однородности дисперсий этим вариантом критерия Уайта Не отвергается.
При использовании Второго варианта наблюдаемое значение статистики критерия равно ![]() . Число степеней свободы соответствующего распределения хи-квадрат равно
. Число степеней свободы соответствующего распределения хи-квадрат равно ![]() . Вероятность того, что случайная величина, имеющая такое распределение, превысит значение
. Вероятность того, что случайная величина, имеющая такое распределение, превысит значение ![]() , равна
, равна ![]() , так что значение
, так что значение ![]() Меньше критического, а значит, гипотеза однородности дисперсий Не отвергается и этим вариантом критерия Уайта.
Меньше критического, а значит, гипотеза однородности дисперсий Не отвергается и этим вариантом критерия Уайта.
Таким образом, статистические выводы относительно однородности дисперсий случайных составляющих в рассматриваемой модели наболюдений оказались Противоречивыми: гипотеза однородности отвергается критерием Голфелда-Квандта, но не отвергается обоими вариантами критерия Уайта. Как можно объяснить такое противоречие?
· Оба варианта критерия Уайта Асимптотические, тогда как критерий Голдфелда-Квандта учитывает реально имеющееся количество наблюдений.
· Оба варианта критерия Уайта являются Критериями согласия, не настроенными на какой-то Специфический класс альтернатив гипотезе однородности, тогда как использование критерия Голдфелда-Квандта непосредственно связано с альтернативой, выраженной в форме возрастания дисперсий ошибок для соответствующего упорядочения наблюдений. И здесь проявляется общее положение: критерии, построенные с расчетом на Узкий класс альтернатив, оказываются Более мощными по сравнению с критериями, рассчитанными на Более широкий класс альтернатив, т. е. Чаще отвергают нулевую гипотезу, когда она не верна.
Рассмотрим теперь график зависимости стандартизованных остатков ![]() от номера наблюдений и его вариант в виде зависимости от года наблюдения:
от номера наблюдений и его вариант в виде зависимости от года наблюдения:

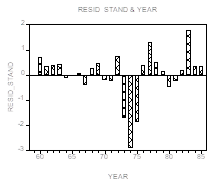
Здесь обращает на себя внимание наличие серий остатков Одинакового знака, что сигнализирует о том, что ошибки в модели наблюдений скорее всего имеют Положительную автокорреляцию. Для 26 наблюдений и ![]() объясняющих переменных границы для критического значения статистики Дарбина-Уотсона при
объясняющих переменных границы для критического значения статистики Дарбина-Уотсона при ![]() (односторонний критерий) равны
(односторонний критерий) равны
![]()
В то же время, вычисленное по остаткам от оцененной модели значение статистики Дарбина-Уотсона равно
![]() ,
,
Что Меньше нижней границы ![]() Следовательно, нулевая гипотеза о выполнении стандартных предположений отклоняется в пользу гипотезы о Положительной автокоррелированности ошибок.
Следовательно, нулевая гипотеза о выполнении стандартных предположений отклоняется в пользу гипотезы о Положительной автокоррелированности ошибок.
Сравним результаты применения критерия Дарбина-Уотсона с результатами, получаемые при использовании критерия Бройша-Годфри.
Если исходить из допущения зависимости очищенных случайных ошибок только На один шаг![]() , как это делается при использовании критерия Дарбина-Уотсона, то в этом случае вычисленное значение статистики критерия Бройша-Годфри равно
, как это делается при использовании критерия Дарбина-Уотсона, то в этом случае вычисленное значение статистики критерия Бройша-Годфри равно ![]() , что соответствует
, что соответствует ![]() -значению, равному
-значению, равному ![]() . Гипотеза независимости ошибок Отвергается, что Согласуется с результатом, полученным при использовании критерия Дарбина-Уотсона.
. Гипотеза независимости ошибок Отвергается, что Согласуется с результатом, полученным при использовании критерия Дарбина-Уотсона.
В то же время, если взять ![]() , то тогда
, то тогда ![]() , что соответствует
, что соответствует ![]() -значению, равному
-значению, равному ![]() . Гипотеза независимости ошибок в этом случае Не отвергается при установленном уровне значимости
. Гипотеза независимости ошибок в этом случае Не отвергается при установленном уровне значимости ![]() , что Расходится с результатом, полученным при использовании критерия Дарбина-Уотсона. Эта гипотеза не отвергается также при выборе
, что Расходится с результатом, полученным при использовании критерия Дарбина-Уотсона. Эта гипотеза не отвергается также при выборе ![]()
![]() ,
, ![]()
![]() и т. д., и это вполне объяснимо: выбор
и т. д., и это вполне объяснимо: выбор ![]() ,
, ![]() ,
, ![]() соответствует выбору все более широких альтернатив по сравнению с
соответствует выбору все более широких альтернатив по сравнению с ![]() , что приводит к Уменьшению вероятности отвергнуть гипотезу независимости ошибок в случае, когда она не верна.
, что приводит к Уменьшению вероятности отвергнуть гипотезу независимости ошибок в случае, когда она не верна.
Проверим, наконец, предположение о нормальном распределении ошибок. Сначала рассмотрим диаграмму «квантиль-квантиль»(Q-Q plot) и диаграмму плотности (DPP-plot):
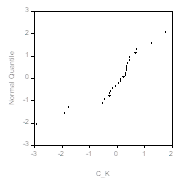
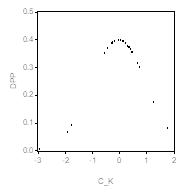
Первая диаграмма не выглядит удовлетворительной; вторая обнаруживает определенную асимметрию. Выборочный коэффициент асимметрии равен здесь -1.285, а выборочный коэффициент эксцесса равен 5.321. Оба эти значения говорят отнюдь не в пользу нормальности ошибок. Статистика критерия Jarque-Bera Принимает значение 12.997, что соответствует ![]() Следовательно, имеющиеся данные не подтверждают гипотезу о выполнении стандартных предположений об ошибках и по этому критерию.
Следовательно, имеющиеся данные не подтверждают гипотезу о выполнении стандартных предположений об ошибках и по этому критерию.
В связи со столь неутешительными результатами в отношении проверки гипотезы выполнения стандартных предположений в рассмотренном примере, возникает естественный вопрос о том, Как именно влияют нарушения этих предположений на статистические выводы.
Неоднородность дисперсий ошибок (гетероскедастичность, heteroscedasticity). Этот вид нарушений стандартных предположений характерен для статистических данных, относящихся к одному моменту времени, но собранных по различным регионам, различным предприятиям, различным социальным группам (Данные в сечениях, cross-section data). Неоднородность дисперсий возникает также как результат тех или иных Структурных изменений в экономике, например связанных с мировыми экономическими кризисами. Последний пример как раз и иллюстрирует подобную ситуацию: резкое возрастание абсолютных величин остатков в этом примере относится к периоду глобального нефтяного кризиса.
Последствия неоднородности дисперсий ошибок:
· Оценки дисперсий случайных величин ![]() (оценок коэффициентов линейной модели) оказываются смещенными.
(оценок коэффициентов линейной модели) оказываются смещенными.
· Построенные Доверительные интервалы для ![]() не соответствуют заявленным уровням значимости.
не соответствуют заявленным уровням значимости.
· Вычисленные значения ![]() - и
- и ![]() - отношений уже Нельзя рассматривать как наблюдаемые значения случайных величин, имеющих
- отношений уже Нельзя рассматривать как наблюдаемые значения случайных величин, имеющих ![]() - и
- и ![]() -распределения, соответствующие стандартным предположениям. Поэтому сравнение вычисленных значений
-распределения, соответствующие стандартным предположениям. Поэтому сравнение вычисленных значений ![]() - и
- и ![]() - отношений с квантилями указанных
- отношений с квантилями указанных ![]() - и
- и ![]() -распределений может приводить к ошибочным статистическим выводам в отношении гипотез о значениях коэффициентов линейной модели.
-распределений может приводить к ошибочным статистическим выводам в отношении гипотез о значениях коэффициентов линейной модели.
Автокоррелированность (сериальная корреляция) ошибок (autocorrelation, serial correlation). Этот вид нарушений стандартных предположений характерен для статистических данных, развернутых во времени (Продольные данные, longitudial data). Автокоррелированность ошибок обычно возникает вследствие направильной спецификации модели, например, при невключении в модель существенной объясняющей переменной с выраженной автокорреляцией.
Последствия автокоррелированности ошибок:
· Оценка ![]() дисперсии случайных ошибок Смещена вниз в случае положительной и Смещена вверх в случае отрицательной автокоррелированности ошибок.
дисперсии случайных ошибок Смещена вниз в случае положительной и Смещена вверх в случае отрицательной автокоррелированности ошибок.
· Оценки дисперсий случайных величин ![]() (оценок коэффициентов линейной модели) оказываются заниженными в случае положительной и Завышенными в случае отрицательной автокоррелированности ошибок.
(оценок коэффициентов линейной модели) оказываются заниженными в случае положительной и Завышенными в случае отрицательной автокоррелированности ошибок.
· Построенные Доверительные интервалы для ![]() не соответствуют заявленным уровням значимости: В случае положительной автокоррелированности ошибок построенные интервалы Неоправденно узки, а В случае отрицательной автокоррелированности ошибок неоправданно широки.
не соответствуют заявленным уровням значимости: В случае положительной автокоррелированности ошибок построенные интервалы Неоправденно узки, а В случае отрицательной автокоррелированности ошибок неоправданно широки.
· Вычисленные значения ![]() - и
- и ![]() - отношений Нельзя рассматривать как наблюдаемые значения случайных величин, имеющих
- отношений Нельзя рассматривать как наблюдаемые значения случайных величин, имеющих ![]() - и
- и ![]() -распределения, соответствующие стандартным предположениям. Поэтому сравнение вычисленных значений
-распределения, соответствующие стандартным предположениям. Поэтому сравнение вычисленных значений ![]() - и
- и ![]() - отношений с квантилями указанных
- отношений с квантилями указанных ![]() - и
- и ![]() -распределений может приводить к ошибочным статистическим выводам в отношении гипотез о значениях коэффициентов линейной модели. Вычисленные значения
-распределений может приводить к ошибочным статистическим выводам в отношении гипотез о значениях коэффициентов линейной модели. Вычисленные значения ![]() - и
- и ![]() - отношений Завышены в случае положительной и Занижены в случае отрицательной автокоррелированности ошибок.
- отношений Завышены в случае положительной и Занижены в случае отрицательной автокоррелированности ошибок.
При обнаружении нарушений стандартных предположений следует либо улучшить спецификацию модели, привлекая подходящие дополнительные объясняющие переменные, либо использовать для оценивания коэффициентов и оценивания дисперсий коэффициентов модели специальные методы оценивания, принимающие во внимание обнаруженные нарушения (далее мы рассмотрим два таких метода: Взвешенный метод наименьших квадратов и Авторегрессионное преобразование переменных).
| < Предыдущая | Следующая > |
|---|