3.1. Проверка адекватности подобранной модели имеющимся статистическим данным: графические методы
Весь рассмотренный нами комплекс процедур получения статистических выводов для линейной модели регрессии (простой или множественной) Опирается на вполне Определенные предположения о модели наблюдений.
В связи с этим, большие значения коэффициента детерминации ![]() (близкие к 1) или статистическая значимость коэффициентов вовсе не обязательно говорят о том, что подобранная модель действительно хорошо Соответствует характеру статистических данных (Адекватна статистическим данным).
(близкие к 1) или статистическая значимость коэффициентов вовсе не обязательно говорят о том, что подобранная модель действительно хорошо Соответствует характеру статистических данных (Адекватна статистическим данным).
В этом отношении весьма поучителен искусственный пример с четырьмя различными множествами данных, которые имеют Качественно различные диаграммы рассеяния и в то же время приводят при использовании модели наблюдений
![]()
К одним и тем же (в пределах двух знаков после запятой) оценкам параметров, значениям коэффициента ![]() И
И ![]() - статистик. Эти множества данных приведены в следующей таблице.
- статистик. Эти множества данных приведены в следующей таблице.
|
Множество 1 |
Множество 2 |
Множество 3 |
Множество 4 | |||||
|
I |
X |
Y |
X |
Y |
X |
Y |
X |
Y |
|
1 |
20 |
16.06 |
20 |
18.28 |
20 |
14.92 |
16 |
13.16 |
|
2 |
16 |
13.90 |
16 |
16.28 |
16 |
13.54 |
16 |
11.52 |
|
3 |
26 |
15.16 |
26 |
17.48 |
26 |
25.48 |
16 |
15.42 |
|
4 |
18 |
17.62 |
18 |
17.54 |
18 |
14.22 |
16 |
17.68 |
|
5 |
22 |
16.66 |
22 |
18.52 |
22 |
15.62 |
16 |
17.94 |
|
6 |
28 |
19.92 |
28 |
16.20 |
28 |
17.68 |
16 |
14.08 |
|
7 |
12 |
14.48 |
12 |
12.26 |
12 |
12.16 |
16 |
10.50 |
|
8 |
8 |
8.52 |
8 |
6.20 |
8 |
10.78 |
38 |
25.00 |
|
9 |
24 |
21.68 |
24 |
18.26 |
24 |
16.30 |
16 |
11.12 |
|
10 |
14 |
9.64 |
14 |
14.52 |
14 |
12.84 |
16 |
15.82 |
|
11 |
10 |
11.36 |
10 |
9.48 |
10 |
11.46 |
16 |
17.98 |
Для всех четырех множеств
Подобранная модель линейной связи имеет вид ![]() ,
,
![]() имеет (оцененную) стандартную ошибку
имеет (оцененную) стандартную ошибку ![]()
![]() имеет (оцененную) стандартную ошибку
имеет (оцененную) стандартную ошибку ![]()
![]() -статистика для проверки нулевой гипотезы
-статистика для проверки нулевой гипотезы ![]() равна 2.67, что соответствует
равна 2.67, что соответствует ![]() -значению 0.026,
-значению 0.026,
![]() -статистика для проверки нулевой гипотезы
-статистика для проверки нулевой гипотезы ![]() равна 4.24, что соответствует
равна 4.24, что соответствует ![]() -значению 0.002,
-значению 0.002,
![]() .
.
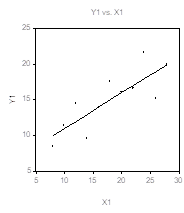
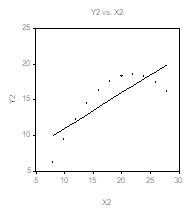
Однако диаграммы рассеяния различаются коренным образом:


Уже чисто визуальный анализ четырех диаграмм рассеяния показывает, что
Только первое множество данных можно признать удовлетворительно описываемым линейной моделью наблюдений
![]()
Для второго множества более подходящей представляется модель
![]()
В третьем множестве выделяется одна точка (3-е наблюдение), которая существенно влияет на наклон и положение подбираемой прямой.
Четвертое множество совершенно непригодно для подбора линейной зависимости, поскольку подобранная прямая фактически определяется наличием одного выпадающего наблюдения
Метод наименьших квадратов достаточно устойчив к малым отклонениям от стандартных предположений, в том смысле, что при таких малых отклонениях статистические выводы на основе анализа модели в основном сохраняются. Однако Существенные отклонения от стандартных предположений могут серьезно исказить выводы на основе статистического анализа модели. В связи с этим необходимо
Иметь Возможность обнаружения отклонений от стандартных предположений,
Иметь инструментарий для коррекции выявленных отклонений от стандартных предположений, позволяющий проводить строгий и информативный анализ статистических данных.
Эффективным средством обнаружения отклонений от стандартных предположений о линейной модели наблюдений
![]()
Является Анализ остатков, т. е. анализ разностей
![]()
Наблюдаемые разности ![]() мы, в силу случайности значений
мы, в силу случайности значений ![]() в модели наблюдений, можем рассматривать как значения соответствующих случайных величин
в модели наблюдений, можем рассматривать как значения соответствующих случайных величин ![]() , за которыми сохраним те же обозначения
, за которыми сохраним те же обозначения ![]() .
.
Если выполнены наши стандартные предположения о модели наблюдений, то остатки ![]() , рассматриваемые как случайные величины
, рассматриваемые как случайные величины ![]() , имеют нулевые математические ожидания
, имеют нулевые математические ожидания
![]()
И дисперсии
![]()
Где ![]() —
— ![]() -й диагональный элемент квадратной
-й диагональный элемент квадратной ![]() -матрицы
-матрицы
![]()
Таким образом, несмотря на то, что дисперсии ошибок![]() Равны между собой при наших предположениях (все они равны
Равны между собой при наших предположениях (все они равны ![]() ), дисперсии остатков, вообще говоря, Различны.
), дисперсии остатков, вообще говоря, Различны.
Для выравнивания дисперсий можно перейти к рассмотрению нормированных остатков

Для которых
Поскольку значение ![]() опять не известно, вместо нормированных остатков приходится использовать «Стьюдентизированные» Остатки
опять не известно, вместо нормированных остатков приходится использовать «Стьюдентизированные» Остатки
![]()
Где, как обычно, ![]() .
.
Во многих пакетах программ величины ![]() в знаменателе правой части выражения для
в знаменателе правой части выражения для ![]() Игнорируются, что приводит к так называемым «Стандартизованным» Остаткам
Игнорируются, что приводит к так называемым «Стандартизованным» Остаткам
![]()
Так сделано, например, в пакете EXCEL. Практический анализ показывает, что графики остатков ![]() и
и ![]() обычно мало отличаются по характеру поведения. Поэтому для предварительного Графического анализа Адекватности вполне можно удовлетвориться значениями
обычно мало отличаются по характеру поведения. Поэтому для предварительного Графического анализа Адекватности вполне можно удовлетвориться значениями ![]() . К тому же, можно показать, что
. К тому же, можно показать, что
![]()
(![]() — количество объясняющих переменных), так что если
— количество объясняющих переменных), так что если ![]() (
(![]() много меньше
много меньше ![]() ), то «в среднем» значения
), то «в среднем» значения ![]() достаточно малы.
достаточно малы.
Графики стандартизованных (стьюдентизированных) остатков позволяют выявлять Типичные отклонения от стандартных предположений о модели наблюдений по характеру поведения остатков. При этом имеется в виду, что, по крайней мере при большом количестве наблюдений, поведение остатков ![]() , должно Имитировать поведение ошибок
, должно Имитировать поведение ошибок ![]() . Иначе говоря, поскольку мы предполагаем, что ошибки
. Иначе говоря, поскольку мы предполагаем, что ошибки ![]() — независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение
— независимые в совокупности случайные величины, имеющие одинаковое нормальное распределение ![]() , то ожидаем, что поведение последовательности остатков
, то ожидаем, что поведение последовательности остатков ![]() должно имитировать поведение последовательности независимых в совокупности случайных величин, имеющих одинаковое нормальное распределение
должно имитировать поведение последовательности независимых в совокупности случайных величин, имеющих одинаковое нормальное распределение ![]() . Соответственно, от стандартизованных остатков можно было бы ожидать поведения, похожего на поведение последовательности независимых в совокупности случайных величин, имеющих одинаковое стандартное нормальное распределение
. Соответственно, от стандартизованных остатков можно было бы ожидать поведения, похожего на поведение последовательности независимых в совокупности случайных величин, имеющих одинаковое стандартное нормальное распределение ![]() .
.
Строго говоря, последнее ожидание не вполне верно. Именно, хотя стандартизованные остатки и имеют распределения, близкие (хотя бы при больших ![]() ) к стандартному нормальному, они Не являются взаимно независимыми случайными величинами. Это можно понять хотя бы из того, что (как мы помним) при использовании оценок наименьших квадратов алгебраическая сумма остатков равна нулю, так что каждый остаток линейно выражается через остальные остатки. Тем не менее при большом количестве наблюдений наличие такого соотношения между остатками практически не делает картину поведения стандартизованных остатков сколь-нибудь существенно отличной от поведения последовательности независимых в совокупности случайных величин, имеющих одинаковое стандартное нормальное распределение
) к стандартному нормальному, они Не являются взаимно независимыми случайными величинами. Это можно понять хотя бы из того, что (как мы помним) при использовании оценок наименьших квадратов алгебраическая сумма остатков равна нулю, так что каждый остаток линейно выражается через остальные остатки. Тем не менее при большом количестве наблюдений наличие такого соотношения между остатками практически не делает картину поведения стандартизованных остатков сколь-нибудь существенно отличной от поведения последовательности независимых в совокупности случайных величин, имеющих одинаковое стандартное нормальное распределение ![]() .
.
Наиболее часто для Диагностики (проверки на наличие) типичных отклонений используют Графики зависимости стандартизованных остатков (как ординат) от
Оцененных значений ![]() ;
;
Отдельных объясняющих переменных;
Номера наблюдения, если наблюдения производятся в последовательные моменты времени с равными интервалами.
График зависимости ![]() От
От ![]() позволяет выявлять три довольно распространенных дефекта модели:
позволяет выявлять три довольно распространенных дефекта модели:
Выделяющиеся наблюдения (outliers) — наличие Отдельных наблюдений, для которых либо математическое ожидание ошибки ![]() существенно отличается от нуля либо дисперсия ошибки
существенно отличается от нуля либо дисперсия ошибки ![]() существенно превышает величину
существенно превышает величину ![]() дисперсий остальных ошибок. Подобные наблюдения могут обнаруживать себя на указанном графике как наблюдения со «слишком большими» по абсолютной величине остатками. Такая ситуация возникает, например, при подборе прямой по третьему (из четырех рассматривавшихся выше) множеству данных:
дисперсий остальных ошибок. Подобные наблюдения могут обнаруживать себя на указанном графике как наблюдения со «слишком большими» по абсолютной величине остатками. Такая ситуация возникает, например, при подборе прямой по третьему (из четырех рассматривавшихся выше) множеству данных:

Неоднородность дисперсий (heteroscedasticity), например, в форме той или иной функциональной зависимости ![]() от величины
от величины ![]() . Так, если рассматриваемый график имеет вид
. Так, если рассматриваемый график имеет вид
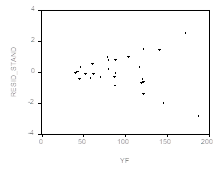
То это скорее всего отражает Возрастание дисперсий ошибок с ростом значений ![]() .
.
Неправильная спецификация модели в отношении множества объясняющих переменных, приводящая к нарушению соотношения ![]() , так что
, так что ![]() . Такая ситуация возникает, например, при оценивании второго множества данных из четырех рассматривавшихся выше:
. Такая ситуация возникает, например, при оценивании второго множества данных из четырех рассматривавшихся выше:

График зависимости ![]() От значений
От значений ![]()
![]() -й Объясняющей переменной полезен для выявления Нелинейной зависимости
-й Объясняющей переменной полезен для выявления Нелинейной зависимости ![]() От
От ![]() -й Объясняющей переменной. Например, для второго из четырех искусственных множеств данных имеем
-й Объясняющей переменной. Например, для второго из четырех искусственных множеств данных имеем
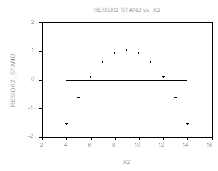
График зависимости остатков от номера наблюдения Полезен в случае, когда наблюдения производятся Последовательно во времени (через равные интервалы времени). По такому графику можно обнаружить
Изменение дисперсии ошибок с течением времени
Невключение в модель переменных, зависящих от времени и существенно влияющих на объясняемую переменную:
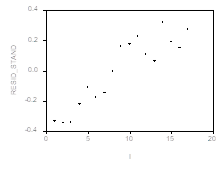
Невыполнение условия независимости в совокупности случайных ошибок ![]() в форме их Автокоррелированности. Более подробно о такой форме статистической зависимости между случайными ошибками мы поговорим позднее, а сейчас продемонстрируем, как выглядят графики остатков в случае Положительной автокоррелированности (левый график) и в случае Отрицательной автокоррелированности (правый график):
в форме их Автокоррелированности. Более подробно о такой форме статистической зависимости между случайными ошибками мы поговорим позднее, а сейчас продемонстрируем, как выглядят графики остатков в случае Положительной автокоррелированности (левый график) и в случае Отрицательной автокоррелированности (правый график):

В первом случае проявляется Тенденция сохранения знака остатка при переходе к следующему наблюдению (за положительным остатком скорее следует также положительный остаток, а за отрицательным — отрицательный). Во втором случае проявляется Тенденция смены знака остатка при переходе к следующему наблюдению (за положительным остатком скорее следует отрицательный остаток, а за отрицательным — положительный).
Отдельную группу составляют графические методы проверки Предположения о нормальности распределения случайных составляющих![]() .
.
Диаграмма «квантиль-квантиль» (Q-Q plot). Для построения этой диаграммы значения стандартизованных остатков ![]() упорядочивают в порядке возрастания; упорядоченные значения образуют ряд
упорядочивают в порядке возрастания; упорядоченные значения образуют ряд
![]()
Если теперь для каждого ![]() нанести в прямоугольной системе координат на плоскости точку с абсциссой
нанести в прямоугольной системе координат на плоскости точку с абсциссой ![]() и ординатой
и ординатой
![]()
(![]() — квантиль уровня уровня
— квантиль уровня уровня ![]() стандартного нормального распределения), то полученные
стандартного нормального распределения), то полученные ![]() точек
точек![]() ,
,![]() , В случае нормальности распределения ошибок должны располагаться Вдоль прямой, имеющей угловой коэффициент, близкий к единице. Подобное расположение имеют точки на диаграмме, построенной указанным способом по первому из четырех множеств искусственных данных:
, В случае нормальности распределения ошибок должны располагаться Вдоль прямой, имеющей угловой коэффициент, близкий к единице. Подобное расположение имеют точки на диаграмме, построенной указанным способом по первому из четырех множеств искусственных данных:
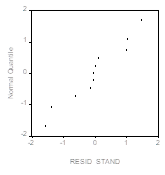
Замечание. Если в последней процедуре не проводить стандартизацию остатков, а использовать непосредственно остатки ![]() , то полученные точки
, то полученные точки![]() ,
,![]() , также будут располагаться (при нормальном распределении ошибок) вдоль некоторой прямой, но уже имеющей угловой коэффициент, Не обязательно близкий к единице.
, также будут располагаться (при нормальном распределении ошибок) вдоль некоторой прямой, но уже имеющей угловой коэффициент, Не обязательно близкий к единице.
Указанное свойство диаграммы «квантиль-квантиль» основано на том, что При больших значениях ![]() имеет место приближенное равенство
имеет место приближенное равенство
![]()
Последнему соответствует приближенное равенство
![]()
— соотношение, используемое для проверки нормальности ошибок в пакете EXCEL.
Диграмма плотности (DP-plot, DPP) Отличается от диаграммы «квантиль-квантиль» тем, что по оси ординат вместо значений квантилей ![]() откладываются значения Функции плотности стандартного нормального распределения
откладываются значения Функции плотности стандартного нормального распределения ![]() . Такая диаграмма дает возможность при достаточном количестве наблюдений не только проверить согласие с предположением о нормальном распределении ошибок, но и выявить характер альтернативного распределения в случае отклонения распределения ошибок от нормального. В качестве примера приведем диаграмму плотности, построенную по остаткам, полученным в результате подбора модели линейной зависимости совокупных расходов на личное потребление от совокупного располагаемого личного дохода (данные по США в млрд. долларов 1982 г., за период с 1959 по 1985 г.):
. Такая диаграмма дает возможность при достаточном количестве наблюдений не только проверить согласие с предположением о нормальном распределении ошибок, но и выявить характер альтернативного распределения в случае отклонения распределения ошибок от нормального. В качестве примера приведем диаграмму плотности, построенную по остаткам, полученным в результате подбора модели линейной зависимости совокупных расходов на личное потребление от совокупного располагаемого личного дохода (данные по США в млрд. долларов 1982 г., за период с 1959 по 1985 г.):
На этой диаграмме обнаруживается определенная асимметрия, что представляется не вполне согласующимся с предположением о нормальности ошибок. Однако сразу делать на этом основании вывод о нарушении такого предположения не следует. Дело в том, что при небольшом количестве наблюдений структура подобной диаграммы весьма неустойчива. Поэтому даже При заведомо нормальном распределении ошибок мы редко увидим вполне симметричную картину расположения точек на диаграмме при малом количестве наблюдений.
Ядерные (kernel) оценки плотности — еще один метод получения суждений о форме функции плотности, позволяющий, в отличие от двух предыдущих, получать график в виде Непрерывной кривой. Существует много разных вариантов таких оценок, в детали которых мы вдаваться не будем, а отметим только, что в пакете EVIEWS предлагается на выбор 8 вариантов, в рамках которых имеется еще и возможность варьирования параметров. Вариант, применяемый по умолчанию, дает для только что рассмотренных данных следующую оценку плотности распределения ошибок:

Как видим, и такой подход дает график, не очень похожий на график функции плотности стандартного нормального распределения, но это опять может быть вызвано малым количеством наблюдений (27).
| < Предыдущая | Следующая > |
|---|