Приложение. 12 полезных советов
Напоследок хочется рассказать о некоторых полезных свойствах программы SPSS, которые существенно облегчат работу с ней.
1. Несколько файлов (баз данных) SPSS можно объединять, добавляя при этом либо новые переменные, либо новых респондентов.
Чтобы добавить поля (переменные) в базу данных SPSS, подготовьте два файла данных (за один цикл можно объединить только два файла). В обоих файлах — реципиенте (база данных, в которую следует добавить переменные) и доноре (база данных, в которой содержатся добавляемые переменные) — необходимо, во-первых, проследить, чтобы имена добавляемых переменных не повторяли имя файла-реципиента; во-вторых, создать ключевое поле, то есть переменную, уникальным образом идентифицирующую респондентов. Обычно эту роль берет на себя номер анкеты. Отсортируйте оба файла по этой переменной (одинаковым образом: по возрастанию или убыванию). При помощи меню Data ► Merge Files ► Add Variables в открывшемся диалоговом окне выберите эту ключевую переменную; затем выберите параметр Match case on key variables in sorted files; поместите ключевую переменную в поле Key Variables. Щелкните на кнопке ОК, и в файл-реципиент будут добавлены новые переменные из файла-донора (после всех существующих переменных).
Добавление респондентов происходит следующим образом. Убедитесь, что оба файла (реципиент и донор) содержат одинаковые переменные (по имени и типу). Откройте диалоговое окно добавления респондентов при помощи меню Data ► Merge Files ► Add Cases. В нем будут автоматически отобраны и помещены в файл-реципиент только одинаковые переменные. После щелчка на кнопке О К изменения вступят в силу: новые респонденты будут добавлены в конец рабочего файла.
2. Построенные диаграммы можно изменять, дважды щелкнув на них мышью в окне SPSS Viewer. Простые диаграммы, как будет показано в п. 3, содержат лишь базовые возможности форматирования диаграмм (в специальном окне SPSS Chart Editor), тогда как интерактивные диаграммы предоставляют значительный набор средств, аналогичных MS Microsoft Excel.
3. Графическая подсистема SPSS позволяет строить обычные (Simple) и интерактивные (Interactive) диаграммы. Вторые отличаются от первых более широкими возможностями форматирования. Однако какой бы тип диаграммы вы ни выбрали, они все равно не будут иметь такого же привлекательного вида, как диаграммы в Microsoft Excel. Диаграммы, выводимые в качестве дополнительного параметра в различных статистических процедурах (меню Analyze), - это только обычные диаграммы. Они предназначены исключительно для использования в процессе анализа данных аналитиками и не подходят для презентаций. Обычные диаграммы можно строить и отдельно от статистических процедур — при помощи меню Graphs. При этом если, скажем, в Microsoft Excel все диаграммы могут быть «на лету» преобразованы одна в другую, то в SPSS однажды построенная диаграмма может менять только элементы форматирования. Наиболее часто используемые виды диаграмм: Ваг (гистограмма), Line (график), Pie (сектограмма) и Scatter (точечная). Интерактивные диаграммы доступны посредством меню Graphs ► Interactive, которое также содержит четыре типа наиболее часто используемых видов диаграмм. Обычные и интерактивные диаграммы могут быть как плоскими, так и объемными.
4. Таблицы в окне SPSS Viewer можно изменять, дважды щелкнув на них мышью. Далее выберите в меню Pivot пункт Pivoting Trays. Откроется дополнительное окно, с помощью которого можно поменять местами столбцы, ряды и уровни таблицы.
5. После создания таблиц линейных или перекрестных распределений на их основе можно строить различные диаграммы. Дважды щелкните на таблице мышью, чтобы открыть ее. Затем выделите требуемые числовые значения (без названий переменных и вариантов ответа) и щелкните правой кнопкой мыши. В появившемся контекстном меню выберите Create Graph и в нем — требуемый тип диаграммы. После этого, например, будет построена интерактивная диаграмма.
6. Меню Analyze ► Custom Tables предоставляет доступ к диалоговым окнам, предназначенным для построения одно - и многомерных таблиц. При помощи этих окон вы можете создавать более презентабельные таблицы, чем Frequencies или Crosstabs. Мы рекомендуем использовать диалоговое окно Multiple Response Tables для работы с многовариантными переменными (вместо стандартной процедуры Analyze ► Multiple Response).
7. Часто при работе с SPSS возникает необходимость скопировать результаты работы программы из окна SPSS Viewer в Microsoft Word или Microsoft Excel. Для того чтобы скопировать диаграмму, выделите ее, щелкнув на ней правой кнопкой мыши, и в открывшемся контекстном меню выберите пункт Сору. Таблицы копируются методами, различными для Microsoft Word и Microsoft Excel. Так, чтобы скопировать таблицу в Microsoft Excel, выделите ее правой кнопкой мыши и в открывшемся меню выберите пункт Сору. После этого вставка в Microsoft Excel производится обычным способом. В Microsoft Word вы можете вставить таблицу, во-первых, в виде рисунка (метафайла) — выделите ее при помощи правой кнопки мыши и выберите пункт Copy Objects (при этом таблицу нельзя изменять) — и, во-вторых, в виде собственно таблицы. Однако если вы просто скопируете и вставите ее в Microsoft Word, таблица потеряет оформление и может стать нечитаемой. Мы рекомендуем вставлять таблицу в Microsoft Word, предварительно скопировав ее в Microsoft Excel.
8. В любых диалоговых окнах SPSS, так же как и в окне SPSS Viewer, вы можете получить справку по конкретным элементам (кнопкам, полям, статистикам) — для этого щелкните на них правой кнопкой мыши. Чтобы уточнить смысл какой-либо статистики, представленной в объектах SPSS Viewer, сначала нужно открыть их двойным щелчком мыши, а затем при помощи правой кнопки мыши получить информацию об интересующей статистике.
9. Весьма мощным средством работы с SPSS для опытных исследователей является командный синтаксис (Syntax). С его помощью можно, во-первых, автоматизировать повторяющиеся операции (например, построение 30 регрессий), а во-вторых, получать доступ к статистическим процедурам, не выведенным в основное меню программы (например, MANOVA). Краткое описание командного синтаксиса заняло бы много страниц. Тем не менее даже начинающие аналитики, не имеющие опыта работы с ним, могут достаточно эффективно использовать командный синтаксис, изучая автоматически генерируемые при работе с меню команды. Для того чтобы увидеть внутреннюю команду синтаксиса при работе с какой-либо статистической процедурой, следует предварительно выбрать в меню Edit ► Options на вкладке Viewer параметр Display commands in the log. После этого все ваши действия будут автоматически отображаться в окне SPSS Viewer в виде простого текста, который можно скопировать в окно Syntax (вызывается при помощи меню File ► New ► Syntax).
10. Не следует путать программный синтаксис (Syntax) со встроенным языком программирования SPSS (Script). Окно программирования открывается при помощи меню File ► New ► Script. Язык программирования SPSS похож на Microsoft Visual Basic for Applications (VBA), однако он содержит отдельные функции, специфичные для работы со структурой базы данных формата SPSS. Встроенный язык программирования весьма беден на визуальные средства интерактивного пользовательского интерфейса, однако он может с успехом применяться в качестве клиента автоматизации, то есть для интегрирования различных приложений, поддерживающих VBA (например, все приложения Microsoft Office) с SPSS. При помощи этого языка можно, например, строить графики в Microsoft Excel или формировать демонстрационные отчеты в Microsoft Word.
11. Командный синтаксис SPSS обладает многими возможностями полноценного макроязыка. В нем есть переменные, циклы, условные операции и т. д. Однако в некоторых случаях языка синтаксиса оказывается недостаточно. Мы рекомендуем использовать командный синтаксис для операций с матрицей данных, то есть с анкетами респондентов, находящимися в окне Data View. Иными словами, проводить такие операции, как чистка базы данных (корректировка пропущенных значений, логической структуры ответов и т. п.), формирование исходного списка переменных в окне Variable View, «подвешивание» меток переменных, а также операции с отдельными ячейками данных (например, копирование-вставка из других программ). Для операций с результатами расчетов (таблицами, результатами статистических тестов и т. д.), расположенными в окне SPSS Viewer, рекомендуется использовать другой встроенный язык программирования SPSS — язык скриптов. Практика показывает, что большинство компаний, занимающихся маркетинговыми исследованиями, производят обработку таблиц, построенных в SPSS, в других программах (чаще всего в MS Excel). Ниже мы покажем, как при помощи языка скриптов SPSS автоматизировать процесс переноса таблиц из окна SPSS Viewer в MS Excel (для построения диаграмм) и в MS Word.
Мы уже не раз упоминали о слабости графической подсистемы SPSS. В связи с этим исследователи строят диаграммы в MS Excel, копируя их из окна SPSS
Viewer. Этот процесс может стать «узким местом» всего исследования, так как при большом объеме таблиц с линейными и перекрестными распределениями процесс построения диаграмм занимает весьма значительный период времени. Давайте посмотрим, как можно легко и быстро автоматизировать данный процесс. Итак, предположим, что у нас есть 100 таблиц с линейными распределениями по различным вопросам анкеты. Все эти таблицы находятся в окне SPSS Viewer. Откройте редактор скриптов SPSS при помощи меню File ► New ► Script. Появится диалоговое окно Use Starter Script, которое предлагает использовать текст уже написанной программы в качестве шаблона для нашего скрипта. Мы будем создавать скрипт самостоятельно, поэтому просто щелкните на кнопке Отмена. Появится окно редактора скриптов SPSS, содержащее полноценную среду разработки (IDE). Слева вы увидите две вкладки — 1 и 2. Мы будем писать скрипт1 на установленной по умолчанию вкладке 1. Скрипты в SPSS пишутся на VBA-совместимом языке Sax Basic. Его возможности в целом более ограничены по сравнению с VBA (а средства разработки диалоговых окон не выдерживают никакой критики). В окне редактора скриптов SPSS по умолчанию введены начальная и конечная строки программы:
Sub Main
End Sub
|
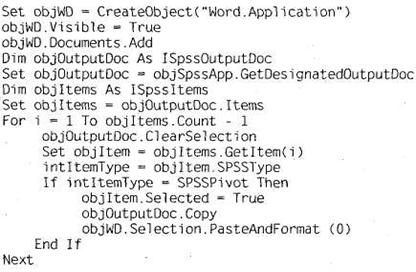 |
Пользователь не должен изменять эти строки. Весь текст программы записывается между данными двумя строками2. Для переноса всего содержимого окна SPSS Viewer в MS Word следует ввести в редакторе скриптов следующий текст (листинг П. 1).
После того как вы введете этот текст в окно редактора скриптов SPSS, запустите его на выполнение при помощи щелчка на кнопке с символом ► на панели инструментов или просто нажав F5. В результате выполнения данной программы будет создан новый документ MS Word, содержащий все таблицы из окна SPSS Viewer.
 |
Для того чтобы перенести все таблицы из окна SPSS Viewer в MS Excel, нужно ввести между начальной и конечной строками программы в редакторе синтаксиса следующий текст (листинг П.2).
В результате выполнения данной программы будет создана новая рабочая книга MS Excel, в которой на каждой вкладке будет одна таблица из окна SPSS Viewer. Далее можно написать макрос (например, на VBA) для построения диаграмм на основании таблиц, содержащихся в MS Excel.
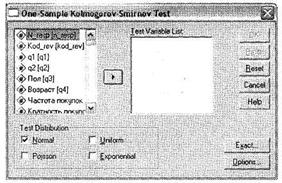
12. И наконец, последнее. Согласно статистической теории, чтобы сделать возможным применение большинства статистических процедур, данные должны подчиняться закону нормального распределения. Если это не так, теоретически вместо стандартных тестов следует проводить непараметрические тесты. На практике (в маркетинговых исследованиях) данные оказываются нормально распределены редко. Более того, многие исследователи просто игнорируют данный теоретический постулат, считая данные, не подчиняющиеся нормальному распределению, выбросами (случайными значениями). Данная техника действительно оправдывает себя во многих примерах маркетинговых исследований, когда от абсолютной точности построенных статистических моделей ровным счетом ничего не зависит. Ведь исследователей в большинстве случаев интересует лишь общее направление различий, связей и т. п. В этом и заключается специфика маркетинговых исследований: нас не интересует, как ведет себя каждый респондент в выборке, — нам интересно знать, как ведут себя целевые группы. В частности, по этой причине в настоящем пособии мы не приводили проверку данных на нормальное распределение в качестве обязательного предварительного этапа статистического анализа. Если вас все же заинтересует форма распределения данных, это легко выяснить при помощи критерия Колмогорова-Смирнова. Откройте соответствующее диалоговое окно при помощи меню Analyze ► Nonparametric Tests ► 1-Sample K-S. На рис. П.1 показан общий вид данного окна.
Для того чтобы протестировать какую-либо переменную на нормальность распределения, перенесите ее из левого списка всех доступных переменных в область для тестируемых переменных Test Variable List. Затем выберите тип распределения, на соответствие которому вы собираетесь проводить тестирование. По умолчанию выбран только тест на нормальное распределение (Normal). Также можно провести тест на распределение Пуассона (Poisson), равномерное (Uniform) и экспоненциальное распределение (Exponential). Как в тесте %2 (см. раздел 4.1), тесты на вид распределения можно проводить асимптотическими методами и точными методами (Exact). Точные методы могут применяться в тех случаях, когда асимптотические методы неприменимы (например, при малых размерах выборки). Мы рекомендуем всегда проверять результаты асимптотических методов при помощи точных. Вывод точных тестов на вид распределения осуществляется при помощи кнопки Exact. Вид соответствующего диалогового окна аналогичен виду окна для теста %2. Напомним, что в нем следует выбрать параметр Monte-Carlo и указать доверительный уровень 95 %.
 |
|
 |
|
В результатах данного теста (окно SPSS Viewer) наше внимание должна привлечь значимость тестовой характеристики: асимптотическая (строка Asymp. Sig. (2-tai-led)) и точная (строка Monte Carlo Sig.). На рис. П.2 представлен общий вид выводимых результатов при тесте на нормальное распределение. Так как нулевая (исходная) гипотеза для тестирования состоит в наличии нормального распределения, вероятность (статистическая значимость) менее 0,05 означает, что исследуемая переменная не подчиняется закону нормального распределения. Таким образом, значимая тестовая величина означает отсутствие, а незначимая — наличие исследуемого распределения.
| < Предыдущая |
|---|