5.1.2. Дискриминантный анализ
Дискриминантный анализ является более универсальной статистической процедурой по сравнению с рассмотренными выше методами логистической регрессии. Основным результатом проведения дискриминантного анализа являются (также как для логистической регрессии) рассчитанные вероятности попадания каждого респондента в ту или иную группу, а также переменная, кодирующая принадлежность их к данным группам. Наряду с этой информацией по результатам дискриминантного анализа можно составить уравнение дискриминантной функции.
В табл. 5.2 приведены основные характеристики переменных, участвующих в дис-криминантном анализе.
Таблица 5.2. Основные характеристики переменных, участвующих в анализе
|
Дискриминантный анализ | |||
|
Зависимые переменные |
Независимые переменные | ||
|
Количество |
Тип |
Количество |
Тип |
|
Одна |
Номинальная Порядковая |
Любое |
Любой |
При выборе зависимой переменной для дискриминантного анализа следует помнить, что увеличение числа категорий в ней практически всегда влечет уменьшение качества статистической модели, то есть ее точности и надежности. Поэтому рекомендуется использовать в качестве зависимых переменные с малым количеством категорий (или преобразовывать существующие переменные к данному виду).
Для описания процесса проведения дискриминантного анализа применим следующие исходные данные. Проводится маркетинговое исследование потенциального спроса на услуги нового развлекательного комплекса. Респонденты в ходе опроса отвечают на вопрос Будете ли Вы посещать новый комплекс? (q26) с вариантами ответа Да и Нет. В качестве независимых переменных, характеризующих респондентов, выделены:
■ возраст (ql8);
■ род занятий (ql9);
■ среднемесячный доход (q20);
■ количество членов семьи (q21);
■ среднемесячные расходы на досуг (q22);
■ пол (q23).
В результате дискриминантного анализа мы разделим респондентов на посетителей и не посетителей нового центра на основании выделенных социально-демографических характеристик опрошенных.
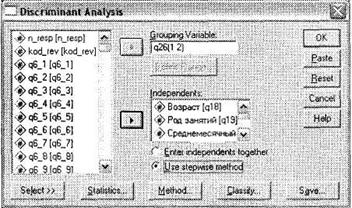 |
Откройте диалоговое окно Discriminant Analysis при помощи меню Analyze ► Classify ► Discriminant (рис. 5.16). Поместите переменную q26 в поле для зависимых переменных Grouping Variable, а анализируемые независимые переменные — в область Independents. Выберите пошаговый метод ввода независимых переменных в модель (параметр Use stepwise method).
|
Далее щелкните на кнопке Define Range для определения границ изменения зависимой переменной q26 (рис. 5.17). В нашем случае минимальным значением (Minimum) является 1, а максимальным (Maximum) — 2.
При помощи диалогового окна Statistics, активизируемого одноименной кнопкой, следует задать вывод результатов одномерного дисперсионного анализа (параметр
 |
Univariate ANOVA), теста Box (параметр Box's M), а также нестандартизированых коэффициентов регрессии (параметр Unstandardized) (рис. 5.18).
|
 |
|
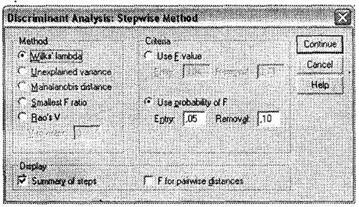
В следующем диалоговом окне, Stepwise Method, вызываемом при помощи кнопки Method, следует выбрать параметр Use probability of F (рис. 5.19). Активизация данного параметра позволяет проводить введение переменных в регрессионную модель более гибко по сравнению с абсолютным значением F-статистики (параметр, выбранный по умолчанию).
В следующем диалоговом окне, Classification, нас интересует только один параметр — Summary Table (рис. 5.20),
Наконец, при помощи кнопки Save можно создать в исходном файле данных новые переменные, содержащие для каждого респондента в выборке прогнозируемую принадлежность к группе (параметр Predicted group membership) и вероятность попадания каждого респондента в данные группы (параметр Probabilities of group membership; см. рис. 5.21).
После выполнения вышеописанных шагов щелкните на кнопке 0К, чтобы запустить программу дискриминантного анализа на исполнение. После окончания расчетов в окне SPSS Viewer будут выведены результаты расчетов.
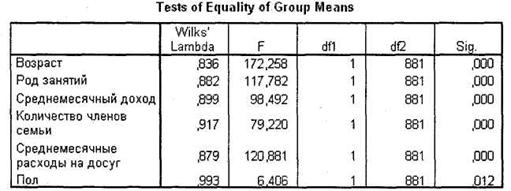
Первой важной для нас таблицей является Tests of Equality of Group Means (рис. 5.22). Она показывает, насколько значимо выбранные независимые переменные разделяют выборочную совокупность респондентов на исследуемые группы. В нашем случае получены весьма значимые результаты для всех исследуемых переменных (Sig. < 0,05). Это свидетельствует о том, что на их основании исследуемые группы зависимой переменной существенно различаются.
 |
Следующая таблица, Test Results, показывает результаты теста Box на значимость различия между категориями исследуемой зависимой переменной (рис. 5.23). В нашем случае данный тест показывает весьма высокую вероятность того, что данные различия являются статистически значимыми (Sig. < 0,001).
 |
| |
|
 |
|
 |
|
 |
|
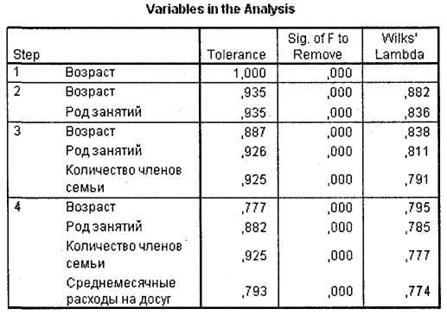
Таблица Variables in the Analysis показывает, какие независимые переменные оказались включенными в итоговую дискриминантную модель на последнем шаге анализа (напомним, что мы выбрали пошаговый метод включения переменных в модель). В нашем случае последним шагом является шаг 4. На четвертом шаге у нас остались четыре независимые переменные из шести (рис. 5.24).
 |
|
Таблица Eigenvalues позволяет оценить качество разделения респондентов на заданные группы зависимой переменной (рис. 5.25). Соответствующий вывод можно сделать исходя из корреляционного коэффициента (столбец Canonical Correlation). В нашем случае данный коэффициент примерно равен 0,5, что свидетельствует о неудовлетворительном результате.
Еще одним важным показателем в этой таблице является собственное значение дискриминантной функции (столбец Eigenvalue). В общем случае большие значения Eigenvalues указывают на высокую точность подобранной дискриминантной функции. В нашем случае рассматриваемое собственное значение весьма мало, что является негативным фактом. Необходимо отметить, что при наличии у зависимой переменной более двух категорий в ходе дискриминантного анализа строится несколько дискриминантных функций (по количеству категорий зависимой переменной минус 1).
Следующая таблица (рис. 5.26) также позволяет оценить качество приближения дискриминантной модели. В нашем случае статистическая значимость (Sig. < 0,001)
 |
указывает на существенные различия между средними значениями дискриминантных функций в двух исследуемых группах зависимой переменной.
|
 |
|
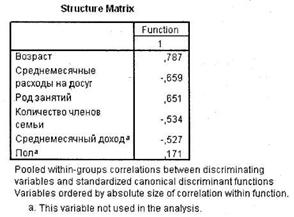
Следующие две таблицы (рис. 5.27 и 5.28) позволяют оценить, насколько отдельные независимые переменные, применяемые в дискриминантной функции, коррелируют с ее стандартизированными коэффициентами. В первой таблице приводятся стандартизированные коэффициенты, а во второй — корреляционные коэффициенты. При помощи стандартизированных коэффициентов, кроме всего прочего, можно непосредственно сравнивать относительный вклад каждой независимой переменной в различение двух исследуемых групп. Например, мы видим, что возраст респондентов влияет на их желание/нежелание посещать новый центр в 1,3 раза сильнее, чем род занятий.
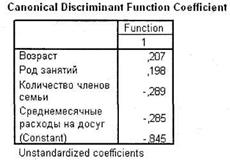
Далее следуют коэффициенты дискриминантной функции (нестандартизирован-ные), на основании которых и строится дискриминантное уравнение, по форме похожее на уравнение регрессии (рис. 5.29). Это просто множители при соответствующих переменных. С учетом константы уравнение дискриминантной функции имеет вид:
Z=-0,845 + 0,207 × Возраст + 0,198 × Род_занятий - 0,289 × Кол-во_членов_семьи - 0,285 × Среднемесячные_расходы_на_досуг
Теперь на основании данного уравнения молено рассчитать вероятность, с которой та или иная социально-демографическая целевая группа респондентов будет посещать новый центр. Подставив в дискриминантное уравнение соответствующие значения, можно сделать вывод о том, что студенты в возрасте 20 лет, проживающие одни и расходующие на свой досуг $ 50 в месяц, скорее всего, будут посещать новый развлекательный центр (вероятность 79 %)'.
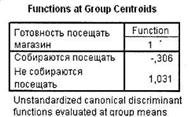
Таблица, представленная на рис. 5.30, показывает средние значения дискриминантной функции в каждой анализируемой группе зависимой переменной.
 |
 |
|
|
|
 |
 |
|
 |
Завершает вывод результатов дискриминантного анализа таблица Classification Results, в последней строке которой содержится информация о точности построенной модели (рис. 5.31). В нашем случае мы видим, что 77,7 % респондентов были корректно отнесены к одной из двух исследуемых групп (77,7% of original grouped cases correctly classified). Результаты оценки корректности классификации варьируются в пределах от 50 % до 100 %, поэтому полученный нами результат — примерно 78 % — можно считать удовлетворительным.
|
| < Предыдущая | Следующая > |
|---|