1.5.1. Модификация и отбор данных. Условный отбор данных и случайная выборка
Этап модификации и отбора данных объединяет целый ряд процедур, используемых для манипуляции с имеющимися данными: условный отбор данных, формирование случайной выборки, сортировка данных, перекодирование переменных, вычисление новых переменных и т. д. В настоящем разделе мы рассмотрим наиболее часто используемые методы автоматизированного управления переменными и их значениями в базах данных SPSS.
1.5.1.1. Отбор анкет по условию
В настоящем параграфе мы рассмотрим такие методы манипуляций с данными, как отбор респондентов по определенному условию (например, выбор из всей базы данных только анкет мужчин), а также формирование случайной выборки.
Часто при анализе данных в SPSS возникает необходимость отбора только тех респондентов, которые соответствуют определенным требованиям (например, имеют среднемесячный доход свыше $ 1000). В этом случае используют условный отбор данных. Соответствующее диалоговое окно вызывается при помощи меню Data ► Select Cases.
Как вы видите на рис. 1.15,.это диалоговое окно не только позволяет осуществлять условный отбор данных, но и разрешает многие другие манипуляции. При проведении маркетинговых исследований наиболее часто применяются только два параметра: If condition is specified (Условный отбор данных) и Random sample of cases (Формирование случайной выборки). По умолчанию установлен параметр All cases, что означает выбор всех без исключения респондентов.
|
 |
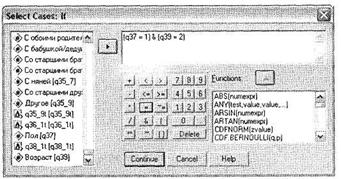
Выберите параметр If condition is specified и щелкните на кнопке If. Откроется новое диалоговое окно Select Cases: If, позволяющее задать условие, согласно которому будет производиться отбор респондентов (рис. 1.16). Основная рекомендация относительно работы с данным диалоговым окном — заключайте все уравнения (название переменной и ее значение) в круглые скобки. Соблюдение данного требования весьма полезно при составлении длинных последовательностей условий.
|
 |
В табл. 1.3 представлена расшифровка всех логических и арифметических операндов, используемых при составлении условных выражений. Такие же операнды используются и в других диалоговых окнах, описываемых в разделе 1.5. Это стандартные операнды для составления логических выражений.
Необходимо отметить, что все логические операторы, кроме = и ~=, применимы только для числовых переменных (не для текстовых).
Помимо представленных стандартных логических операторов, существуют специальные предустановленные функции (область Functions) — при щелчке правой кнопкой мыши на любой из них появляется описание соответствующей функции.
Таблица 1.3. Стандартные логические операторы, используемые в SPSS
|
Арифметические |
Логические | ||
|
Оператор |
Значение |
Оператор |
Значение |
|
+ |
Сложение (x + y) |
< |
Меньше (x < y) |
|
- |
Вычисление (x - y) |
> |
Больше (x > y) |
|
* |
Умножение (x * y) |
<= |
Меньше или равно (x <= y) |
|
/ |
Деление (x / y) |
>= |
Больше или равно (x >= y) |
|
** |
Возведение в степень (x ** y) |
= |
Равно (x = y) |
|
() |
Приоритет вычислений |
~= |
Не равно (x ~ y) |
|
| |
Или (x | y) |
& |
И (x & y) |
|
~ |
Отрицание (~ x) |
В приведенном примере мы выбрали все анкеты, полученные от респондентов, являющихся мужчинами (вопрос q37, вариант ответа 1) в возрасте от 26 до 30 лет (вопрос q39, вариант ответа 2). Щелкнув на кнопке Continue и завершив операцию при помощи щелчка на кнопке 0К в главном диалоговом окне, мы увидим, что респонденты, не соответствующие данному условию, оказались исключенными из рассмотрения (их номера перечеркнуты). Можно не только временно исключить из рассмотрения респондентов, не подходящих под определенное условие, но и полностью удалить такие нерелевантные анкеты из базы данных SPSS. Для этого в диалоговом окне Select cases (рис. 1.15) необходимо заменить выбранный по умолчанию параметр Filtered (в области Unselected Cases Are) на Deleted.
1.5.1.2. Отбор анкет случайным образом
Иногда при обработке данных маркетинговых исследований возникает необходимость отбора респондентов не по конкретному условию, а случайным образом (то есть формирование случайной выборки). Эта возможность весьма полезна для уменьшения размера исходной выборки — например, для выполнения статистических процедур, предъявляющих повышенные требования к вычислительным ресурсам компьютера. Также случайная выборка применяется при проверке корректности работы некоторых статистических процедур (например, факторного анализа): сначала процедура проводится для общей выборки, а затем — для случайной выборки из n-го количества респондентов.
Для формирования случайных выборок в диалоговом окне Select Cases, (см. рис. 1.15) предусмотрен параметр Random sample of cases. Выберите этот параметр и щелкните на кнопке Sample. Открывшееся диалоговое окно (рис. 1.17) содержит два способа формирования случайной выборки: с указанием доли респондентов, которых необходимо отобрать из исходной выборки (Approximately), либо с указанием конкретного количества респондентов, которое необходимо отобрать (Exactly). При этом в последнем случае необходимо также указать в поле from the first... cases количество респондентов, из которого следует осуществить выбор. Для формирования случайной выборки из общего числа опрошенных в данном поле следует указать совокупный размер выборки.
В нашем случае мы случайным образом отобрали 50 % респондентов из исходной выборки.
|
 |
| < Предыдущая | Следующая > |
|---|