05. Задача 1. Корреляционно-регрессионный анализ
В практических задачах, связанных с исследованиями в области экономических проблем, достаточно часто возникают ситуации, когда при описании параметров функционирования экономических систем не имеется полного набора значений параметров и их взаимооднозначного соответствия (когда известны точные и определенные функциональные связи, когда каждому значению одной величины соответствует строго определенное значение другой). При этом, соотношение между переменными таково, что одному значению признака X соответствует не одно, а несколько (спектр) возможных значений признака Y, т. е. известно их распределение. Такие связи обнаруживаются лишь при массовом изучении признаков и называются корреляционными. Задачи подобного типа достаточно часто встречаются в практике управления экономическими объектами.
На практике обычно встречаются ситуации, когда проводится множество экспериментов (наблюдений), во время которых фиксируются определенные значения переменных. Множество значений каждой величины обычно называют Рядом. На основе этих рядов можно попытаться найти математическую зависимость (регрессию), связывающую эти величины. При этом одна из величин (Y1,Y2,...,Yi) выступает в качестве зависимой, а другие (X11,X12,...,X1i;...;Xn1, ...,Xni) - независимых переменных регрессии.
Y = F (X1, X2, .., XN).
Метод корреляционно-регрессионного анализа заключается в нахождении параметров A1, A2 ,..., AN, B аппроксимирующей зависимости вида
YСр = A1×X1 + A2×X2 +...+ AN×XN + B.
При наличии только одного фактора, имеется однофакторная зависимость, которая определяется, обычно, в виде YСр = A1×X1 + B, и такая зависимость называется однофакторной или парной. Форма записи уравнения регрессии зависит от выбора функции, отображающей статистическую связь между фактором и результативным признаком и включает следующие: линейная регрессия, параболическая, кубическая, гиперболическая, полулогарифмическая, показательная, степеннная, нахождение которых сводится к определению параметров регрессионного уравнения и оценке достоверности самого уравнения.
При этом, выборочные значения результативного признака y и фактора x, обычно, представляются в таблице вида:
Таблица 1
Исходные данные
|
№ п\п |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Y |
Y1 |
Y2 |
Y3 |
Y4 |
Y5 |
Y6 |
Y7 |
|
X |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
Нахождение параметров линейной регрессии сводится к оценке тесноты связи показателя от фактора в виде коэффициента корреляции, r
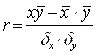 ,
,
Где 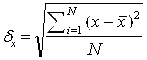
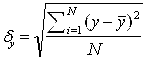 ,
,
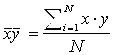 ,
,  ,
, 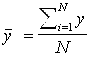
Y - экспериментальное значение показателя;
X - экспериментальное значение фактора;
![]() - среднеквадратическое отклонение по х;
- среднеквадратическое отклонение по х;
![]() - среднеквадратическое отклонение по y.
- среднеквадратическое отклонение по y.
Если коэффициент корреляции r = 0, то считают, что связь между признаками незначительна либо отсутствует, если r = ± 1, то между признаками существует весьма высокая функциональная связь. Таким образом, можно провести качественную оценку тесноты корреляционной связи между признаками, используя таблицу Чеддока (табл.2)
Таблица 2
Таблица Чеддока
|
Диапазон изменения |
0.1 - 0.3 |
03. - 0.5 |
0.5 - 0.7 |
0.7 - 0.9 |
0.9 - 0.99 |
|
Качественная характеристика связи |
Слабая |
Умеренная |
Заметная |
Высокая |
Весьма высокая |
Для нелинейной зависимости коэффициент корреляции заменяется на следующие параметры оценки регрессионного уравнения: корреляционное отношение h (0 £ h £ 1) и индекс корреляции R, которые вычисляются по следующим зависимостям.
![]()
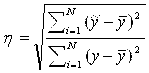 ,
, 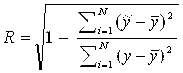 ,
,
Где значение ![]() - значение показателя, вычисленное по регрессионной зависимости.
- значение показателя, вычисленное по регрессионной зависимости.
В качестве оценки точности вычислений используют величину средней относительной ошибки аппроксимации
![]()
Если качественная оценка тесноты связи заметная или высокая, то строят график эмпирической зависимости, используя исходные данные табл.1, на основании которого проводят выбор вида регрессионной зависимости. Для этого, обычно, вычисляют коэффициент корреляции для различных форм связи и ориентируются на ту, значение коэффициента корреляции у которой будет больше.
Для выбранной формы регрессии вычисляются коэффициенты уравнения регрессии. Для линейной формы у = a + bx, находятся коэффициенты a и b, коòîðûå определяются из системы нормальных уравнений. Результаты вычислений включаются в таблицу следующей структуры
|
№ |
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Для выбранной формы регрессии и выборки по которым она строится, устанавливают значимость этих показателей, для чего определяется ошибку коэффициента корреляции по величине среднеквадратичного отклонения
 ,
,
а затем определяют значение нормированного отклонения ![]() .
.
Принято считать, что если ![]() > 2, то с вероятностью 0.95 можно говорить о значимости полученного коэффициента корреляции. Оценка достоверности выборочного коэффициента корреляции устанавливается сопоставлением фактического и табличного нормированных отклонений
> 2, то с вероятностью 0.95 можно говорить о значимости полученного коэффициента корреляции. Оценка достоверности выборочного коэффициента корреляции устанавливается сопоставлением фактического и табличного нормированных отклонений ![]() . Если
. Если ![]() , то считают, что в генеральной совокупности связь между признаками имеется и величина R находится в пределах ошибки аппроксимации. Если же
, то считают, что в генеральной совокупности связь между признаками имеется и величина R находится в пределах ошибки аппроксимации. Если же ![]() , считают, что полученный по выборке коэффициент корреляции не существенен. Для оценки вклада фактора в общую вариацию зависимой переменной используют коэффициент детерминации (квадрат коэффициента корреляции), который рассчитывается так
, считают, что полученный по выборке коэффициент корреляции не существенен. Для оценки вклада фактора в общую вариацию зависимой переменной используют коэффициент детерминации (квадрат коэффициента корреляции), который рассчитывается так ![]() .
.
Для оценки надежности найденного уравнения регрессии применяют F-критерий Фишера
![]()
Если удовлетворяется неравенство Fp < Ft (где Ft - табличное значение критерия Фишера) , то с вероятностью 0.95 считается ненадежной и требуется искать другую форму зависимости.
Для оценки влияния фактора на результативный показатель, используется также коэффициент эластичности, который показывает, на сколько процентов изменяется значение показателя при изменении значения влияющего на него фактора на 1 %
Э = ![]()
где ![]() - производная найденного уравнения регрессии
- производная найденного уравнения регрессии
| < Предыдущая | Следующая > |
|---|