2.01. Вероятностное моделирование ошибок
Мы уже неоднократно сталкивались с вопросом о том, сколь существенно величина коэффициента корреляции (детерминации) должна отличаться от нуля, чтобы можно было говорить о действительно существующей линейной связи между исследуемыми переменными.
Если Оцененное значение эластичности потребления некоторого товара оказалось несколько больше единицы, то возникает вопрос о том, сколь надежным является заключение о том, что потребление этого товара эластично по ценам.
Если мы будем использовать подобранную прямую
![]()
Для прогнозирования значений ![]() для Новых наблюдений
для Новых наблюдений ![]() , t= n+1,...,N +K, то сколь надежными будут такие прогнозы?
, t= n+1,...,N +K, то сколь надежными будут такие прогнозы?
Если у нас нет Теоретических (экономических) оснований для выбора между моделью в уровнях переменных и моделью в логарифмах уровней, то как выбрать одну из этих моделей на основании одних только наблюдений?
Ответы на эти и другие подобные вопросы невозможны, если мы не сделаем некоторых более или менее подробных Предположений о структуре последовательности ошибок ![]() , участвующих в определении модели наблюдений
, участвующих в определении модели наблюдений
![]()
Базовая, и наиболее простая модель для последовательности ![]() предполагает, что
предполагает, что ![]() — Независимые случайные величины, имеющие одинаковое распределение (I. i. d. — independent, identically distributed random variables).
— Независимые случайные величины, имеющие одинаковое распределение (I. i. d. — independent, identically distributed random variables).
Для нас (Пока!) достаточно представлять случайную величину ![]() как переменную величину, такую, что До наблюдения ее значения Невозможно предсказать это значение абсолютно точно, и, в то же время, Для любого
как переменную величину, такую, что До наблюдения ее значения Невозможно предсказать это значение абсолютно точно, и, в то же время, Для любого ![]() ,
, ![]() , определена Вероятность
, определена Вероятность
![]()
Того, что Наблюдаемое значение переменной ![]() Не превзойдет
Не превзойдет ![]() ;
; ![]() . Функция
. Функция ![]() , называется Функцией распределения случайной величины
, называется Функцией распределения случайной величины ![]() (C. d. f. — Cumulative distribution function).
(C. d. f. — Cumulative distribution function).
Говоря об ошибках ![]() как О случайных величинах, мы, соответственно, понимаем указанную линейную модель наблюдений таким образом, что
как О случайных величинах, мы, соответственно, понимаем указанную линейную модель наблюдений таким образом, что
А) Существует (теоретическая, объективная или в виде тенденции) линейная зависимость значений переменной ![]() от значений переменной
от значений переменной ![]() с вполне определенными, хотя обычно и не известными исследователю, значениями параметров
с вполне определенными, хотя обычно и не известными исследователю, значениями параметров ![]() и
и![]() ;
;
Б) эта линейная связь для реальных статистических данных Не является строгой: наблюдаемые значения ![]() переменной
переменной ![]() Отклоняются от значений
Отклоняются от значений ![]() , указываемых моделью линейной связи
, указываемых моделью линейной связи
![]()
В) при Заданных (известных) значениях ![]() Конкретные значения отклонений
Конкретные значения отклонений
![]()
Не могут быть точно предсказаны до наблюдения значений ![]() даже если значения параметров
даже если значения параметров ![]() и
и![]() известны точно;
известны точно;
Г) для каждого ![]() , определена вероятность
, определена вероятность![]() того, что Наблюдаемое значение отклонения
того, что Наблюдаемое значение отклонения ![]() Не превзойдет
Не превзойдет ![]() , причем эта вероятность Не зависит от номера наблюдения;
, причем эта вероятность Не зависит от номера наблюдения;
Д) вероятность того, что наблюдаемое значение отклонения ![]() в I-М наблюдении не превзойдет
в I-М наблюдении не превзойдет ![]() , Не зависит от того, какие именно значения принимают отклонения в остальных
, Не зависит от того, какие именно значения принимают отклонения в остальных ![]() наблюдениях.
наблюдениях.
В дальнейшем, говоря о той или иной случайной величине ![]() , мы Будем предполагать существование функции
, мы Будем предполагать существование функции ![]() , принимающей только Неотрицательные значения и такой, что
, принимающей только Неотрицательные значения и такой, что
1) площадь под кривой
![]()
В прямоугольной системе координат ![]() (точнее, площадь, ограниченная сверху этой кривой и снизу — горизонтальной осью
(точнее, площадь, ограниченная сверху этой кривой и снизу — горизонтальной осью ![]() ) Равна
) Равна ![]() ,
,
2) для любой пары значений ![]() с
с ![]() , вероятность
, вероятность
![]()
Численно равна Площади, ограниченной снизу осью ![]() , сверху — кривой
, сверху — кривой ![]() , слева — вертикальной прямой
, слева — вертикальной прямой ![]() , справа — вертикальной прямой
, справа — вертикальной прямой ![]() (т. е. равна Части площади Под кривой
(т. е. равна Части площади Под кривой ![]() , расположенной Между точками
, расположенной Между точками ![]() и
и ![]() ).
).
3) для любого ![]() , вероятность
, вероятность ![]() того, что наблюдаемое значение
того, что наблюдаемое значение ![]() Не превзойдет
Не превзойдет ![]() , равна площади, ограниченной снизу осью
, равна площади, ограниченной снизу осью ![]() , сверху — кривой
, сверху — кривой ![]() и справа — вертикальной прямой
и справа — вертикальной прямой ![]() , т. е. равна Части площади под кривой
, т. е. равна Части площади под кривой ![]() , расположенной Левее точки
, расположенной Левее точки ![]() .
.
Заметим, что при этом выполняется следующее важное соотношение:
![]()
(Действительно, вероятность ![]() численно равна части площади под кривой
численно равна части площади под кривой ![]() , расположенной Левее точки
, расположенной Левее точки ![]() , а эта часть складывается из части площади под кривой, расположенной Левее точки.
, а эта часть складывается из части площади под кривой, расположенной Левее точки.![]() . и части площади под кривой, расположенной Между точками
. и части площади под кривой, расположенной Между точками ![]() И
И ![]() , так что
, так что
![]()
Откуда и следует заявленное соотношение.) Кроме того,
![]()
(Действительно,
![]()
Поскольку слева складываются части площади под кривой ![]() , расположенные, соответственно, Левее и Правее точки
, расположенные, соответственно, Левее и Правее точки ![]() , так что в сумме они составляют Всю площадь под этой кривой, а вся площадь под кривой
, так что в сумме они составляют Всю площадь под этой кривой, а вся площадь под кривой ![]() как раз и равна 1.)
как раз и равна 1.)
Функция ![]() связана с функцией распределения случайной величины
связана с функцией распределения случайной величины ![]() соотношениями
соотношениями
![]()
И называется Функцией плотности вероятности случайной величины ![]() (P. d.f. — Probability density function). Для краткости, мы часто будем говорить о функции
(P. d.f. — Probability density function). Для краткости, мы часто будем говорить о функции ![]() как о Функции плотности или о Плотности распределения случайной величины
как о Функции плотности или о Плотности распределения случайной величины ![]() .
.
Возьмем два непересекающихся интервала значений переменной ![]() :
: ![]() и
и ![]() . Рассмотрим два варианта распределения вероятности случайной величины
. Рассмотрим два варианта распределения вероятности случайной величины ![]() : Равномерное распределение на отрезке
: Равномерное распределение на отрезке ![]() и Треугольное распределение на том же отрезке. Графики функций плотности для этих двух вариантов имеют следующий вид:
и Треугольное распределение на том же отрезке. Графики функций плотности для этих двух вариантов имеют следующий вид:
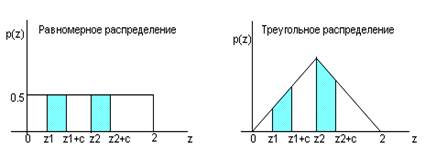
Площади заштрихованных прямоугольников на Первом графике численно равны вероятностям того, что случайная величина ![]() , имеющая Равномерное распределение на отрезке
, имеющая Равномерное распределение на отрезке ![]() , примет значения в пределах
, примет значения в пределах ![]() и
и ![]() , соответственно. Поскольку основания и высоты этих прямоугольников равны, то равны и их площади, т. е. равны указанные вероятности.
, соответственно. Поскольку основания и высоты этих прямоугольников равны, то равны и их площади, т. е. равны указанные вероятности.
Площади заштрихованных трапеций на Втором графике численно равны вероятностям того, что случайная величина ![]() , имеющая Треугольное распределение на отрезке
, имеющая Треугольное распределение на отрезке ![]() , примет значения в пределах
, примет значения в пределах ![]() и
и ![]() , соответственно. Высоты этих трапеций равны, однако стороны трапеции, расположенной правее, больше сторон трапеции, расположенной левее. Поэтому и площадь трапеции, расположенной правее, больше площади трапеции, расположенной левее. А это означает, в свою очередь, что вероятность того, что случайная величина
, соответственно. Высоты этих трапеций равны, однако стороны трапеции, расположенной правее, больше сторон трапеции, расположенной левее. Поэтому и площадь трапеции, расположенной правее, больше площади трапеции, расположенной левее. А это означает, в свою очередь, что вероятность того, что случайная величина ![]() , имеющая треугольное распределение на отрезке
, имеющая треугольное распределение на отрезке ![]() , примет значения в пределах
, примет значения в пределах ![]() , Больше вероятности того, что эта случайная величина
, Больше вероятности того, что эта случайная величина ![]() примет значения в пределах
примет значения в пределах ![]() .
.
Таким образом, функция плотности указывает на Более вероятные и Менее вероятные интервалы значений случайной величины. Если случайная величина ![]() имеет Равномерное распределение на отрезке
имеет Равномерное распределение на отрезке ![]() , то для нее Все интервалы значений, имеющие одинаковую длину и расположенные Целиком в пределах отрезка
, то для нее Все интервалы значений, имеющие одинаковую длину и расположенные Целиком в пределах отрезка ![]() , имеют Одинаковые вероятности (т. е. вероятности попадания значений случайной величины на эти интервалы одинаковы). Если же случайная величина
, имеют Одинаковые вероятности (т. е. вероятности попадания значений случайной величины на эти интервалы одинаковы). Если же случайная величина ![]() имеет Треугольное распределение на отрезке
имеет Треугольное распределение на отрезке ![]() , то для нее интервалы значений, имеющие одинаковую длину и расположенные Целиком в пределах отрезка
, то для нее интервалы значений, имеющие одинаковую длину и расположенные Целиком в пределах отрезка ![]() , имеют, вообще говоря, Различные вероятности: вероятность того, что случайная величина примет значение в интервале, расположенном ближе к центральному значению
, имеют, вообще говоря, Различные вероятности: вероятность того, что случайная величина примет значение в интервале, расположенном ближе к центральному значению ![]() , Больше вероятности того, что случайная величина примет значение в интервале, расположенном ближе к одному из концов отрезка
, Больше вероятности того, что случайная величина примет значение в интервале, расположенном ближе к одному из концов отрезка ![]() .
.
Обсудим несколько более точно вопрос о том, что мы понимаем под Независимостью нескольких случайных величин. Пусть мы имеем ![]() случайных величин
случайных величин ![]() , имеющих Одинаковую функцию распределения
, имеющих Одинаковую функцию распределения ![]() . Мы говорим, что эти случайные величины Независимы в совокупности, Если Для любого набора пар
. Мы говорим, что эти случайные величины Независимы в совокупности, Если Для любого набора пар ![]() ,
, ![]() ,...,
,...,![]() , где
, где ![]() И
И ![]() Могут быть равны также
Могут быть равны также ![]() и
и ![]() ,
,
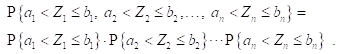
При таком предположении Условная вероятность того, что, например, ![]() , При условии, что
, При условии, что ![]() ,
, ![]() ,
, ![]() , Равна Безусловной вероятности того, что
, Равна Безусловной вероятности того, что ![]() , т. е. вероятности, вычисляемой Без задания указанногоусловия:
, т. е. вероятности, вычисляемой Без задания указанногоусловия:

(Вертикальная черта в этой формуле указывает на то, что первая вероятность — Условная; справа от вертикальной черты записано Условие, при котором вычисляется эта вероятность.) Иначе говоря, на распределение вероятности случайной величины ![]() Не влияет информация о значениях случайных величин
Не влияет информация о значениях случайных величин ![]() . И вообще, на распределение вероятностей случайной величины
. И вообще, на распределение вероятностей случайной величины ![]() Не влияет информация о значениях случайных величин
Не влияет информация о значениях случайных величин ![]() с
с ![]() .
.
Если случайные величины ![]() имеют Одинаковое распределение
имеют Одинаковое распределение ![]() (заданное или функцией распределения или функцией плотности) и Независимы в совокупности, то часто это обозначают в записи следующим образом:
(заданное или функцией распределения или функцией плотности) и Независимы в совокупности, то часто это обозначают в записи следующим образом:
![]() ~
~![]() .
.
Возвращаясь к модели наблюдений
![]()
![]()
И предполагая, что ![]() — Независимые случайные величины, имеющие одинаковое распределение (I. i. d), Мы должны теперь сделать еще и предположение о том, Каким именно является это одинаковое для всех
— Независимые случайные величины, имеющие одинаковое распределение (I. i. d), Мы должны теперь сделать еще и предположение о том, Каким именно является это одинаковое для всех ![]() распределение.
распределение.
| < Предыдущая | Следующая > |
|---|